
Insurance companies are sitting on a data goldmine. Every day, thousands of documents flow through your organization—policy applications, claims submissions, medical evaluations, loss histories, inspection reports, and contractual agreements.
But here’s the problem: approximately 80% of this valuable information exists in unstructured formats. PDFs, scanned images, handwritten forms, and legacy documents that your systems struggle to process efficiently.
Machine Learning is changing this equation entirely. Modern ML-powered data extraction can process insurance documents in seconds, automatically retrieving key information that would take humans hours to find.
Let’s explore how this technology works, why it matters for your insurance operations, and how Kudra AI is helping insurers unlock the value hidden in their document archives.
Understanding Data Extraction in Insurance (It’s More Than Just Reading Text)

Before we dive into machine learning solutions, let’s clarify what we mean by data extraction in the insurance context.
The Difference Between Data Mining and Data Extraction
Data extraction is part of a broader discipline called text mining—an AI-driven technique that transforms unstructured, raw information into structured, usable data. Why does this matter? Because computers can only process and analyze structured information effectively.
Data extraction specifically focuses on identifying and retrieving valuable information from large volumes of text by recognizing entities, attributes, and the relationships between them. Machine learning algorithms power this process, automatically scanning documents and pulling out essential words, phrases, and data points from unstructured insurance content.
Here’s a practical example: Your insurance company receives a pet insurance application. When processing the claim, an agent searches for “canine coverage” in your ML-powered system. Instead of manually reviewing hundreds of documents page by page, the system instantly surfaces only the relevant sections—perhaps 15-20 pages from a much larger archive. It can even highlight exactly where terms like “dog insurance,” “pet coverage,” or “canine policy” appear in context.
This is fundamentally different from simple keyword matching. The ML system understands that “golden retriever,” “family dog,” and “pet canine” all relate to the same insurance category.
The Strategic Benefits of ML-Powered Data Extraction for Insurers
The insurance industry’s digital transformation has accelerated dramatically in recent years. More carriers are moving operations online as a natural evolution from basic digitization to true digital integration.
As data collection and storage increasingly happen in digital formats, insurers gain unprecedented opportunities to leverage this information. ML-based document extraction turns massive data volumes into actionable intelligence, enabling seamless information retrieval and dramatic improvements in operational efficiency.
Key Advantages for Insurance Companies

1. Streamlined Document Processing:
When ML algorithms handle information extraction automatically, operational efficiency improves significantly. Documents that once required manual review get processed much faster, accelerating business workflows and reducing costs by 40-60% according to industry research.
2. Elimination of Manual Data Entry:
Insurance professionals no longer need to personally scan through policies, claims forms, contracts, and agreements hunting for specific information. Instead, they receive extracted data instantly, formatted and ready for integration into your document management systems.
3. Superior Accuracy Through Context Understanding:
ML technology analyzes data by examining correlations and causal relationships. Unlike simple text matching, ML models evaluate words and phrases within their surrounding context, delivering far more accurate results.
The system also recognizes synonyms and related terminology. Searching for “automobile” will surface documents mentioning “vehicle,” “car,” or “sedan.” And here’s the crucial advantage: machine learning systems improve continuously through use. The more your team works with the platform, the more refined and efficient it becomes.
4. Enhanced Customer Experience:
When insurers process claims and complete underwriting faster with greater accuracy, customer loyalty naturally increases. ML-powered data extraction becomes more than an operational tool—it’s a competitive differentiator that directly impacts your market position and customer retention
Primary Use Cases: Where ML Extraction Delivers Maximum Impact
Machine learning data extraction provides value across insurance operations, but two areas show particularly compelling results.
Use Case 1: Accelerating the Underwriting Process
Underwriters assess risk levels for every policy by evaluating comprehensive information packages—financial records, medical histories, property assessments, and more. This analysis traditionally consumes significant time and effort, with critical details often buried deep within hundreds of PDF pages.
ML-based extraction solutions help underwriters access this vital applicant information quickly and efficiently. Processing time for standard cases drops from hours to minutes, freeing underwriters to focus their expertise on complex, high-value risk assessments that truly require human judgment.
The result? Your underwriting team handles more volume without sacrificing quality, and applicants receive decisions faster.
Use Case 2: Transforming Claims Processing
Claims handling represents another document-intensive workflow where extraction technology delivers substantial benefits. The process involves analyzing submissions and supporting materials to verify accuracy, authenticate information, and determine whether to approve or deny each request.
Claims teams must classify submissions by type, match them to appropriate insurance products, assess complexity levels, and screen for potential fraud indicators—all while processing diverse document formats and sources.
ML extraction enables adjusters to retrieve critical information rapidly and accurately. This speeds decision-making, improves cost estimation accuracy, reduces processing time, and minimizes errors throughout the claims settlement workflow.
Faster, more accurate claims handling directly translates to improved customer satisfaction and reduced operational costs.
How ML Data Extraction Actually Works ( The Technology Explained Simply )
When we discuss extracting information from insurance documents, we’re really talking about optical character recognition (OCR)—the technology that makes text machine-readable.
The Challenge of PDF Processing

PDFs present an interesting paradox. On one hand, they’re structured documents that should be straightforward to parse. Numerous tools exist specifically for PDF text extraction.
On the other hand, PDFs were designed to preserve both content and layout across different platforms—which is exactly why they’re so difficult to edit. This design creates complexity for text extraction, with difficulty varying based on what information you need. Are you extracting just plain text? Or do formatting, positioning, and fonts also matter?
Machine learning can handle all these scenarios, but each additional layer of information requires more sophisticated AI models and deeper expertise.
The Two-Stage Extraction Process
Stage 1: Text Detection

First, ML algorithms scan documents to identify where text appears. The system essentially maps the document, isolating regions containing any textual content. One common approach involves drawing bounding boxes around text elements—individual words or character groups get enclosed in separate detection zones.
Stage 2: Text Recognition and Structuring
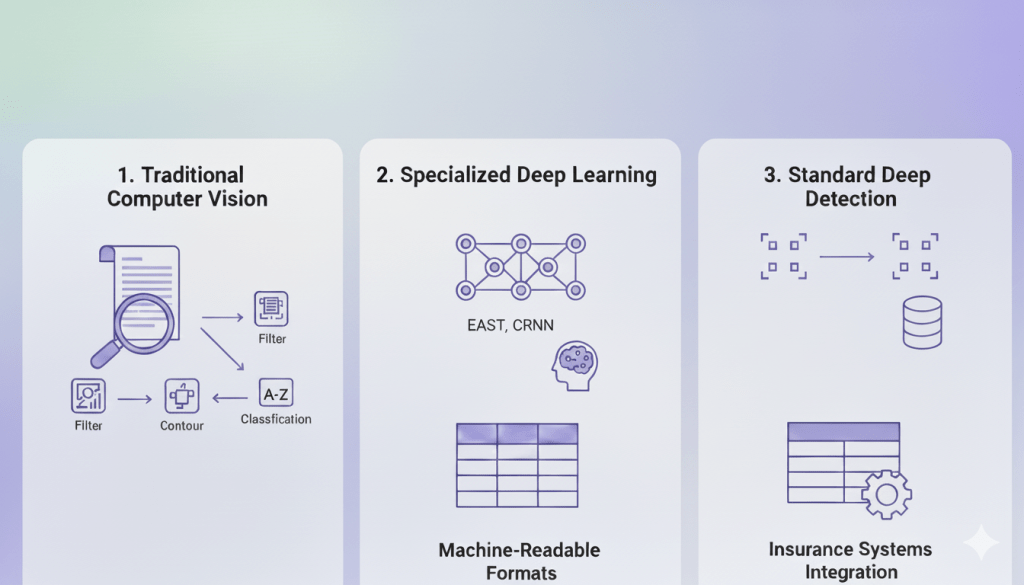
Next, the ML system converts detected text into structured, machine-readable formats that your insurance systems can process. Three main technical approaches exist:
- Traditional Computer Vision Methods: Engineers apply filters to make characters stand out from backgrounds, use contour detection to recognize individual characters, then employ image classification to identify what each character represents.
- Specialized Deep Learning Techniques: These neural network approaches like EAST (Efficient Accurate Scene Text Detector) and CRNN (Convolutional-Recurrent Neural Network) eliminate the need for manual feature selection, letting the network learn optimal extraction patterns automatically.
- Standard Deep Learning Detection: Teams can also leverage proven detection algorithms including SSD (Single-Shot Detector), YOLO (You Only Look Once), and Mask R-CNN (Mask Region-Based Convolutional Neural Network).
Your ML Data Extraction Implementation Roadmap
Implementing ML-powered document extraction follows a structured development process. Here are the essential phases:
Phase 1: Define Business Objectives and Requirements
Start by clearly articulating your goals. What specific documents will you process? What information needs extraction—just text, or also tables, images, and formatting? These decisions drive your technology choices and implementation approach.
Phase 2: Data Assessment and Preparation
Data forms the foundation of any ML solution. Conduct a thorough audit of your data sources, evaluating both quality and quantity. Make informed decisions about data collection strategies and whether supplementing with external datasets makes sense for your use case.
Phase 3: Data Pipeline Development
During this phase, data engineers transform raw information so ML algorithms can process it effectively. This includes designing data pipelines, cleaning and processing documents, and applying necessary transformations.
Phase 4: Model Training and Deployment
Finally, teams build and train the ML models. Dataset size matters less than relevance—quality trumps quantity when it comes to training data. The information you use directly impacts your model’s future accuracy and reliability.
Continuous monitoring ensures the solution performs as expected and improves over time.
The end result should be an intuitive tool that extracts text from PDFs and presents it in meaningful, structured blocks. Ideally, the interface is user-friendly enough that employees without technical backgrounds can operate it confidently.
Why Kudra AI Delivers Superior Results for Insurance Document Extraction

While these general-purpose tools provide solid foundations, insurance companies need more than generic OCR. You need document intelligence specifically designed for insurance workflows, terminology, and compliance requirements.
This is where Kudra AI’s approach differs fundamentally:
Insurance-Specific Model Training
We don’t deploy generic AI and hope it works with your documents. Kudra AI’s models are trained on insurance-specific content from day one—policy forms, claim submissions, medical reports, loss histories, and inspection documents that match what your team actually processes.
The result? Extraction accuracy that exceeds 95% from initial deployment, not after months of learning.
Custom Fine-Tuning for Your Operations
Every insurer has unique document types, terminology, and workflow requirements. Kudra AI offers:
- Model Fine-Tuning: We adjust core AI capabilities to match your specific document formats, coverage types, and accuracy needs. Think of it as training the AI to think like your most experienced processor.
- Prompt Optimization: We refine how the AI interprets different scenarios, reducing false positives and ensuring recommendations align with your business rules and risk philosophy.
Intelligent Document QnA
Beyond extraction, Kudra AI enables conversational interaction with your documents. Adjusters can ask natural language questions:
- “What exclusions apply to this property claim?”
- “Show me this customer’s claim history for the past 3 years”
- “Does this policy cover foundation repairs?”
The AI searches relevant documents, understands context, and provides accurate answers with source citations—turning your document archive into an intelligent knowledge base.
Continuous Learning That Compounds Over Time
Kudra AI models improve continuously based on your team’s feedback and decisions. Every correction, approval, or flag trains the system to perform better next time. Clients typically see extraction accuracy improve by 8-15 percentage points in the first six months as models adapt to their specific needs.
Getting Started: Is Your Organization Ready for ML Data Extraction?
Machine learning data extraction offers transformative potential for insurers who handle substantial document volumes through multiple channels. As an information-driven business, your company should actively explore automation opportunities that turn data into competitive advantage.
However, successful implementation requires specific expertise—both in machine learning/data science and deep insurance industry knowledge.
If your internal teams lack this specialized combination of skills, Kudra AI brings the expertise you need. Our platform is purpose-built for insurance document intelligence, with models trained on millions of insurance-specific documents.
We handle the technical complexity while you focus on insurance operations. Implementation typically takes 4-6 weeks from contract to production, with immediate improvements in processing speed and accuracy.
Your Next Step: See It In Action With Your Own Documents
The insurance industry’s data extraction challenge isn’t going away—it’s growing as document volumes increase. The question isn’t whether to automate, but when to start and who to partner with.
Ready to see what ML-powered extraction can do for your specific documents?
Kudra AI offers a free document assessment: send us 10-20 sample documents (anonymized), and we’ll process them to demonstrate real-world accuracy, speed, and extraction capabilities with your actual content.
No commitment required. Just clear evidence of what’s possible when you unlock the data trapped in your documents.
Contact Kudra AI today to transform manual data extraction into automated intelligence.
About Kudra AI
Kudra AI is the premier document intelligence platform designed specifically for insurance operations. Our ML-powered extraction, custom model training, and intelligent QnA capabilities help insurers process documents faster, more accurately, and more efficiently than ever before. We serve carriers, brokers, MGAs, and TPAs across multiple countries, processing millions of insurance documents annually.
Found This Helpful?
Book a free 30-minute discovery call to discuss how we can implement these solutions for your business. No sales pitch, just practical automation ideas tailored to your needs.
Book A Call