
In today’s fast-paced insurance industry, processing a vast array of documents is a critical but often cumbersome task. Intelligent Document Extraction has emerged as a game-changing solution for insurance companies, streamlining the handling of policy declarations, claims forms, endorsements, and underwriting documents.
By automating the extraction of essential data from these complex documents, Intelligent Document Extraction addresses several challenges faced by the industry:
1- Policy Declarations: These documents contain vital information such as policy numbers, insured names, coverage details, and effective dates. Manually extracting this information is time-consuming and prone to errors, leading to potential mismanagement of policies.
2- Claims Forms: When processing claims, insurance companies must accurately extract claimant details, incident information, and coverage data to expedite the claims process. Manual handling of these forms increases the likelihood of errors and delays in settling claims.
3- Endorsements: Insurance endorsements modify existing policies, requiring the extraction of updated policy information and the tracking of changes. Manual data entry increases the risk of inaccuracies and inconsistencies, which can negatively impact customer satisfaction and regulatory compliance.
4- Underwriting Documents: Efficiently assessing risk and determining appropriate coverage requires extracting essential data from various underwriting documents. Manual extraction slows down the process, leading to delayed decisions and reduced competitiveness in the market.
In this tutorial, we are going to train a custom Natural Language Processing (NLP) model to extract relevant information from policy declaration documents and classify them using zero-shot classification with chatGPT. For the training, we will custom-train a deep-learning model on a labeled dataset. We will then create a custom workflow to integrate our model with chatGPT using Kudra workflow creation feature.
Data Labeling and Model Training
Data Labeling
Our insurance policy declarations comes mostly in unstructured PDF formats with a variety of layouts that depend on the insurance provider. To overcome this challenge, we are going to train a custom NLP model that identifies the specific information we are interestd in. Specifically, we are interested in extracting the following information which is specific to the auto-insurance industry:
POLICYHOLDER MOBILE/CONTACT
AGENT/BROKER EMAIL
INSURANCE COMPANY NAME
PLAN NAME
POLICY NO.
POLICY START DATE
ISSUANCE DATE
POLICY EXPIRY
POLICYHOLDER NAME
POLICYHOLDER ADDRESS
ENGINE NUMBER
CHASSIS NUMBER
VEHICLE NUMBER
TOTAL LIABILITY PREMIUM
TOTAL OWN DAMAGE PREMIUM
GST
NET PREMIUM
GROSS PREMIUM
AGENT/BROKER/INTERMEDIARY CODE
AGENT CONTACT
POLICYHOLDER EMAIL ID
AGENT/BROKER/INTERMEDIARY NAME
PERIOD OF INSURANCE
BODY TYPE
ADD ON PREMIUM
FUEL TYPE
Because no such model exists publicly, we will need to create our own training data and train a custom model. To do so, we will use UBIAI Text Annotation Tool since it supports OCR labeling and model training without any code required,

UBIAI labeling platform. Image by Author.
For the labeling part, it is better to label with a team to increase the labeling quality and reduce bias. This can be done easily in UBIAI as well since it supports comprehensive team management feature.
For this tutorial, we have labeled around 210 policy declaration documents which should be sufficient to get started training the model.
Model Training
To train the model, we use 120 epochs, batch size of 4 and dropout of 0.35. In the backend, UBIAI is using state-of-the-art deep learning model to learn from the labeled dataset and adjust its weights.
The training takes approximately 1.5h running on GPU. Once it’s done, we get back the score for each entity as shown below.
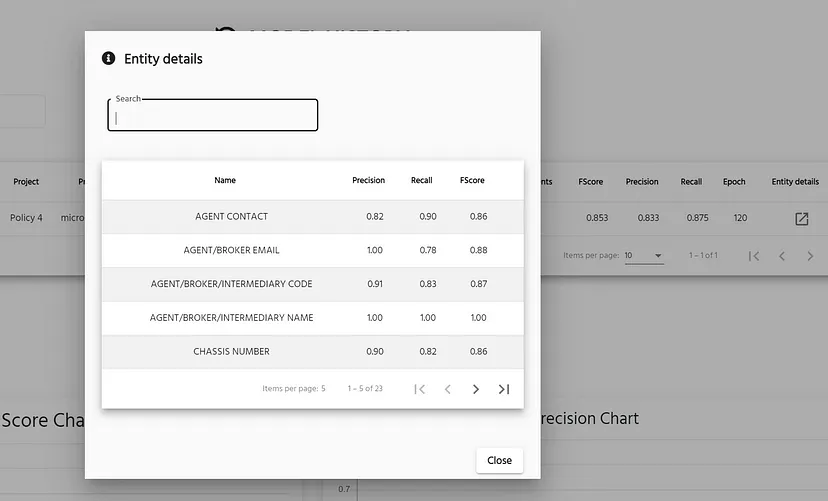
Model performance for each entity. Image by Author
Overall we are getting a relatively good score in the 80% and higher. Although our dataset comes in a variety a formats, we have approximately 7 templates for each vendor overall, so the model was able to generalize fairly quickly even with a small amount of labeled data.
Document Extraction from Insurance Document
We are now ready to deploy our model in production. For this purpose, we are going use the newly launched tool called Kudra where we can deploy our model and connect it to a business workflow with just a few clicks.
Here is a quick introduction to the Kudra app:
The workflow we are interested to create is the following:
1- Import PDF and images
2- OCR
3- Extraction using our new custom AI model
4- Zero-shot Classification using chatGPT: Some documents might contain other insurance policies such as health insurance or home insurance. We would like to correctly classify the one that belongs to auto insurance.

Kudra workflow creation interface. Image by Author.
We are now ready to run our workflow! Simply drag and drop your files and press run:
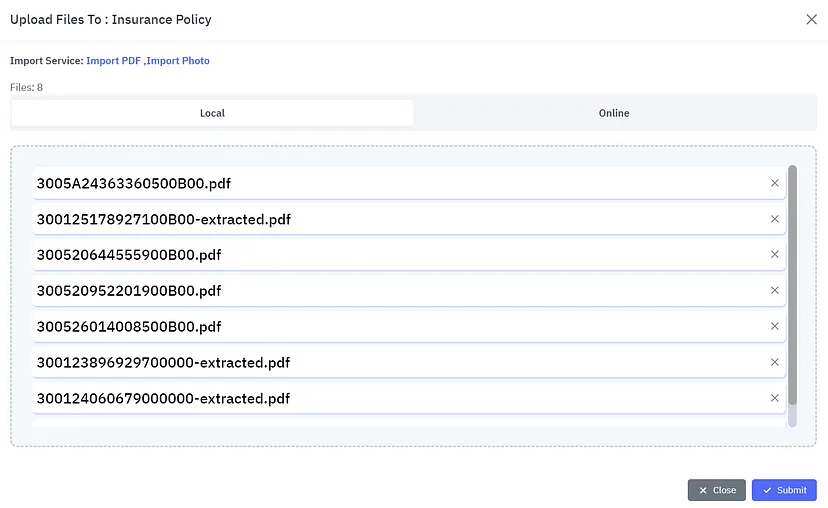
Document upload in Kudra. Image by Author.
After the processing is done, we can visualize the extraction process from our custom workflow:
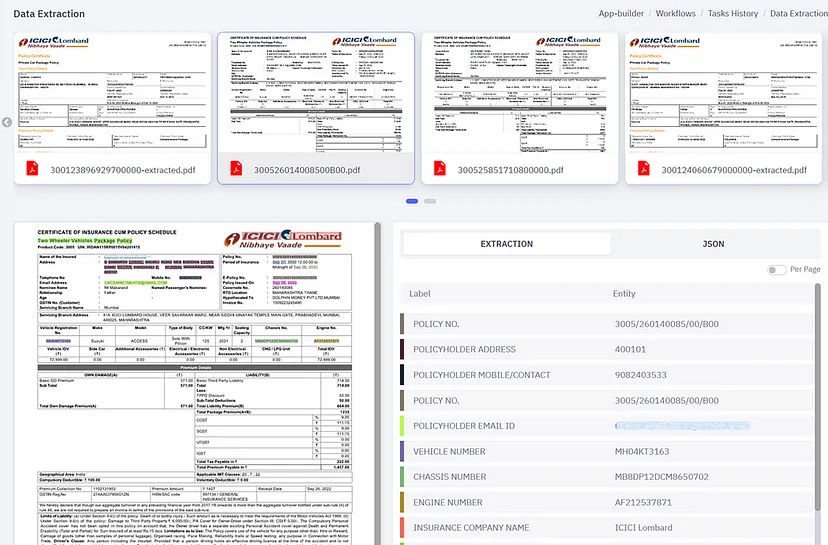
Model output after processing. Image by Author.
Once the data is reviewed, we can extract it as a csv file:
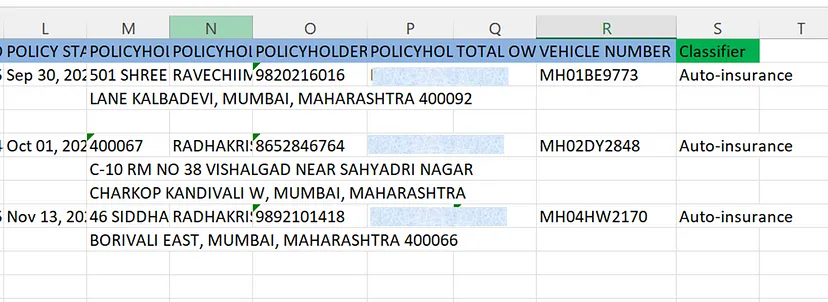
Structured excel file from insurance documents. Image by Author.
The blue columns are the entity extracted using our custom AI model and the green Classifier column is the output of the chatGPT using zero-shot classification.
Using this structured information, insurance agents can perform advanced search and analytics, setup policy expiration reminders, etc. on existing clients based on policy numbers, vehicle numbers, etc.
Conclusion
Intelligent document extraction solutions streamline the laborious task of extracting pertinent information from intricate policy documents, thereby enhancing efficiency and precision.
By reducing manual labor and the risk of human error, it significantly enhances customer satisfaction and bolsters regulatory compliance, key factors in the success of any insurance company. Furthermore, the capability to integrate the custom AI model with large language models such as chatGPT enables the creation of powerful workflows that better solve each business need.
Discover how to streamline claims processing even further with Step-by-Step Guide Using Kudra