
In today’s complex business landscape, organizations face a multitude of risks that can impact their operations and bottom line. Identifying and analyzing these risks, known as risk factor analysis, is crucial for effective decision-making and risk management strategies by investors. Traditionally, this process has relied heavily on manual efforts, often prone to errors and time-consuming. However, with the advent of AI technologies such as deep learning models, organizations now have the opportunity to leverage its power to enhance their risk factor analysis capabilities.
The “risk factors” section found in the 10-K report holds immense value in shedding light on critical areas that often escape the attention of many investors. While the majority of the content consists of standard risk disclosures, it is the insightful examination of factors such as new regulations and laws, market risk, and macroeconomic conditions, that unveils hidden complexities.
In this tutorial, we delve into the key steps involved in training a custom AI model that identifies risk factors from SEC 10-K reports and integrates it into a workflow that analyses the results using chatGPT. We also highlight the importance of human-in-the-loop review for refining the model’s predictions and ensuring the accuracy of extracted risk factors.
Let’s get started!
Extracting Item 1A from 10-K Reports
!pip install sec-api
And run the following script to download Item 1A section:
from sec_api import ExtractorApi
extractorApi = ExtractorApi("YOUR API KEY")
filing_url = "https://www.sec.gov/Archives/edgar/data/1318605/000156459021004599/tsla-10k_20201231.htm"
section_text = extractorApi.get_section(filing_url, "1A", "text")
Labeling and Training Custom AI Model
1. Zero-Shot Labeling
In order to train a custom AI model that identifies the relevant risk factors, we need to label some examples for the model to learn from. The most time consuming and tedious part of the labeling process usually happens at the start of the project when there’s insufficient labeled data to train the first iteration of the AI model. This is particularly prevalent in situations where new categories or classes are introduced, for which there is no pre-existing labeled data.
However, with the emergence of Large Language Models (LLMs), Zero-Shot Labeling (ZSL) has proven to be an excellent way to circumvent the cold start problem. Zero-shot labeling refers to classifying new unseen documents based on the model’s in-context learning capabilities.
For this tutorial, we are interested in extracting the following entities from the text:
COMPANY_NAME
COMPETITOR_NAME
GEOGRAPHICAL_LOCATION
REGULATIONS_AND_LAWS
MACROECONOMIC_TERM
PERSON
RISKS
COMPANY_PRODUCT_NAME
We are going to upload 55 chunks of risk factors extracted from 10-K documents and label them using UBIAI annotation tool. UBIAI is an automated labeling tool that supports both zero-shot and few-shot labeling, here are the main features:
• LLM assisted labeling with zero-shot and few-shot labeling using OpenAI’s GPT 3.5 Model
• Model training and fine-tuning of deep learning models
• Model-assisted labeling using fine-tuned models
• Team collaboration
• OCR Annotation
To enable zero shot labeling, simply go to the Models menu in the annotation page and press Add new Model. Once done, click on settings and select number of example equal to 0. Which means, we are going to perform zero shot labeling based on the description of the entities alone without providing any examples:
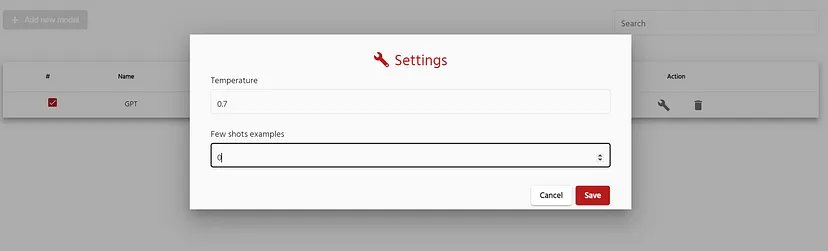
Few shot labeling configuration window. Image by Author
Here is the output of the zero-shot labeling:
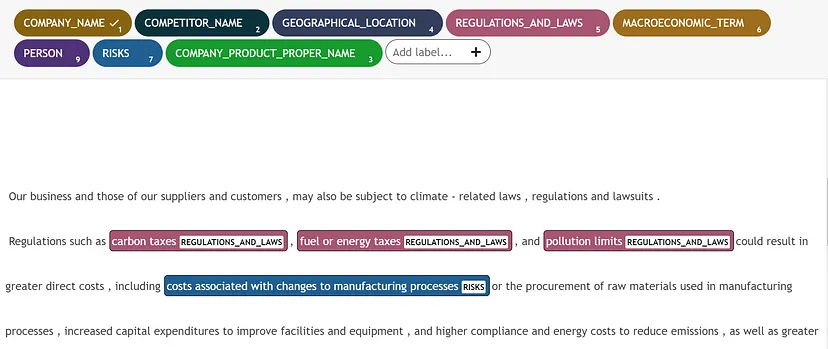
Zero-shot labeling in UBIAI. Image by Author
Although we haven’t provided any examples to learn from, the GPT model was able to extract many entities correctly. But there are still some erroneous extraction that we still need to correct.
2. Few-Shot Labeling
After reviewing and correcting the first document prediction, we feed it to the GPT model to learn from and ask it to label the next document using few shot labeling:
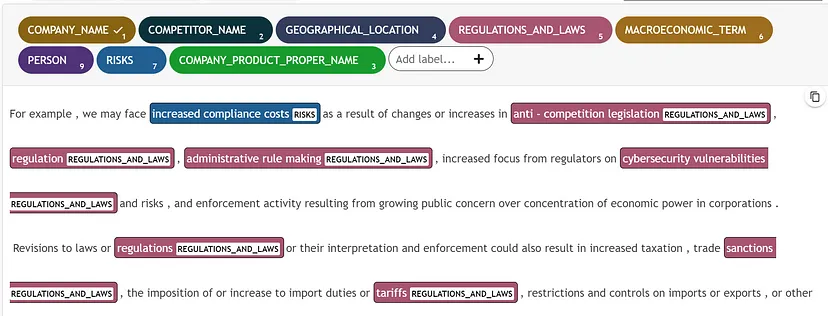
Few-shot labeling in UBIAI. Image by Author
The GPT prediction is overall better with less mistakes but still requiring human review and correction.
Model-Assisted Labeling
everaging LLM assisted labeling and human-in-the-loop review, we can quickly label 55 risk factor documents. Labeling more examples will result in a better model performance, but for this tutorial, we will stick with the 55 labeled examples as a proof of concept.
We are now ready to train a full on custom Named Entity Recognition (NER) model on our labeled dataset. For this task, we will fine-tune a spacy model on our task, and use it to auto-label the rest of our data. This can be done easily in UBIAI:
Model-assisted labeling video.
Risk Factor Analysis with Custom NER Model and chatGPT
Once the model is trained, we can proceed with deploying and integrating the model into a document extraction workflow. The trained model will enable us to identify regulations and laws, risk factors, macroeconomic events, and key persons that can potentially impact the business’s bottom line. By automatically identifying and classifying the relevant risk factors, we will gain valuable insights at scale.
In addition to NER, we can analyze the identified risks using chatGPT and ask it to provide recommendations. chatGPT will act as our analyst and give us valuable feedback about the company’s future.
Integrating the trained model with chatGPT can be easily done using Kudra where we can chain multiple modules together, in this case, custom AI model + chatGPT without any coding required.
Below is an example of the prompt given to chatGPT. [[Input_data]] refers to the output of the previous module Custom Entity Model which will contain the list of identified risks. We then ask chatGPT to analyze the risk factors (we will call it analystGPT) by providing the following prompt:
From the company risk factors listed below, identify the ones that have the most impact on the company’s future revenue, and classify the 5 most impactful factors:
[[input_data]]

Kudra workflow building interface. Image by Author.
We are now ready to run the workflow on a new 10-K report! Let’s run it on the latest IBM 10-K report:

Document extraction review in Kudra. Image by Author
After running the document extraction workflow on the new 10-K report, we obtained insightful results that shed light on the company’s risk factors. The model effectively identified and extracted relevant information, such as regulations, laws, macroeconomic events, and various risks that could influence the company’s bottom line, here are some of them:
Macroeconomic terms:
- Currency fluctuations between the U.S. dollar and non-U.S. currencies
Regulations and laws:
- Economic, Political, Health, and Other Conditions: The company is a globally integrated entity, operating in over 175 countries worldwide and deriving about sixty percent of its revenues from sales outside the United States laws
- Economic and political changes
- Data localization requirements
- Labor relations laws
- IP protection
- Tariffs
- Company’s Financial Results
- GAAP
- Government Clients
- Applicable laws
- Regulations
- Cybersecurity
Risks:
- Investments in R&D
- Damage to IBM Reputation
brand and overall
reputation - Product defects
- Failures, cybersecurity incidents
- Government investigations
- Legal proceedings
- Negative perceptions
- Client adoption rates
- Business and delivery models
- Legal principles and indemnification
- Failure to Achieve Objectives
- Higher Debt Levels
- Litigation
- Failure to close planned transactions
The model identified correctly many of the macroeconomic terms, regulations & laws, and risks that can impact the company’s future. However, in some cases, the entities were mislabeled and some were mixed up. This is expected as the training data (55 examples) was too small to yield a good performance, especially for a semantically complex document such as Item 1A. Further labeling, will certainly result in a much better-named entity extraction.
Now, let’s check the analystGPT recommendation:
1. Investments in R&D
2. Damage to IBM's reputation
3. Product defects, failures, and cybersecurity incidents
4. Failure to achieve objectives
5. Economic, political, health, and other conditions
Reasoning:
Investments in R&D can have the most impact on IBM's future revenue because they are essential for developing innovative products and services that can differentiate the company from competitors and attract new customers.
Damage to IBM's reputation can also have a significant impact on the company's revenue because it can lead to loss of customer trust and loyalty, which can result in reduced sales and market share.
Product defects, failures, and cybersecurity incidents can also have a significant impact on IBM's revenue because they can damage the company's reputation, lead to legal proceedings, and result in loss of customers and revenue.
Failure to achieve objectives can have a significant impact on IBM's revenue because it can lead to lower profitability and reduced market share, as competitors may be able to gain an advantage.
Lastly, economic, political, health, and other conditions can have a significant impact on IBM's revenue because they can affect customer demand and the company's ability to operate and compete in different markets.
AnalystGPT identified the most risky factors but also provided its reasoning behind each one. The top risks such as Investment in R&D, damage to IBM’s reputation and Product defects, failures and cybersecurity incidents appears to be substantiated but further verification by subject matter experts are needed.
Limitations
The approach described in this tutorial has many limitations, here are some of them:
• Item 1A is a complex section of the 10-K report: it can be challenging to distinguish between real risk factors and generic ones. Companies typically use abstractive and deceptive language to hide true risks. Therefore, subject matter experts are needed to label the data correctly.
• The accuracy of the result depends on the performance of the NER model. Focusing on labeling high-quality datasets will be key to achieving good results.
• ChatGPT has a limitation of 4000 tokens which precludes us from sending a long list of entities. Chunking the list of entities will be necessary.
• ChatGPT still suffers from hallucination problems and can create false information even with the provided list of entities from the text itself
Conclusion
The seamless integration of the trained NER model with chatGPT using Kudra enables efficient extraction and analysis of companies’ risk factors. This combination allows for a comprehensive understanding of the identified risks and their potential impact on the company’s future.
By running the workflow on a new 10-K report, the extraction process yields valuable extractions, such as identified regulations and laws, risk factors, macroeconomic events, and key persons. Leveraging chatGPT as a virtual analyst, enhances the analysis process and provides recommendations for the most impactful risk factors.
As future steps:
• We can train the NER model on a bigger dataset to get more accurate results
• In addition to NER, we can train a relation extraction model to identify the relationship between different entities, which will provide more insights into the risk factors.
• Increase the list of entities that chatGPT can analyze by chunking the entity list.