
Buried within the mountains of unstructured documents that businesses generate daily is a treasure trove of data that holds immense potential in driving efficiency and decision-making. Yet traditional methods fail at unleashing this potential. Enter artificial intelligence – with capabilities like machine learning, natural language processing, and computer vision, AI solutions can now rapidly and accurately extract information from these documents.
In this article, we will understand what unstructured documents are, the associated data extraction challenges, and how technologies like AI are automating this process. We will also closely examine Kudra, an intelligent document processing platform that empowers businesses to effortlessly build automated workflows that can extract data from diverse document types with pinpoint precision.
What are Unstructured Documents?
Unstructured data refers to information that does not reside in a traditional row-column database. It lacks a predefined data model and includes formats like emails, PDFs, scanned images, Word documents, digital photos, and even handwritten notes.
By some estimates, over 80% of all business data is unstructured. This includes essential documents like contracts, financial statements, medical records, invoices, shipping manifests, and more. Valuable data is embedded in these documents, but it is not readily extractable for analysis.
For instance, a hospital may have decades’ worth of patient medical records scanned and saved as images. Mining these for data points like symptoms, diagnoses, and prescribed medications is extremely difficult without digitization and organization.
Traditional data extraction methods like Optical Character Recognition (OCR) and manual data entry could be better on unstructured data. They cannot accurately recognize text and context across different formats. This leaves critical business data trapped in documents, unable to be leveraged for insights.
The Shift Towards Document Extraction Automation – Role of AI and Other Technologies
Thankfully, rapid advancements in AI and associated technologies are disrupting traditional data extraction techniques. Applied correctly, these technologies can reliably and quickly convert unstructured documents into machine-readable, structured data.
Specific technologies powering this change include:
• AI and Machine Learning: Algorithms that can “learn” from data patterns and improve in accuracy over time without explicit programming. For instance, an invoice processing AI can be trained on hundreds of sample invoices to recognize sender details, dates, total amounts, and line items.
• Natural Language Processing (NLP): An AI technique that enables understanding and generation of human language, critical for unstructured data. NLP extracts meaning from text documents by analyzing grammar, context, and more.
• Computer Vision: Technology that allows computers to identify, understand, and process images and digital documents in a human-like manner. This aids in scanning complex documents and extracting embedded information.
• Robotic Process Automation (RPA): Automating repetitive, rules-based tasks for data extraction through bots. Useful for high-volume, simple documents.
Kudra: Intelligent Document Extraction Solution
Kudra integrates the above technologies into an intelligent platform that can rapidly build automated workflows for accurate data extraction from diverse document types.
Finance teams can analyze years of historical contracts and purchase orders to determine spending patterns. Logistics companies can track near real-time shipment statuses across regions to identify bottlenecks. Healthcare administrators can seamlessly compile patient statistics for government reporting.
Such use cases highlight the power of Kudra in structuring unstructured data for unprecedented visibility and efficiency gains. Let us examine Kudra’s document processing capabilities in greater detail.
Deep Dive into Kudra’s Document Extraction & Processing Capabilities
Kudra is an AI-based platform with advanced data extraction capabilities across document types and business domains:
• Documents Processed: Contracts, bank statements, invoices, financial reports, shipping manifests, bills of lading, medical records, pay slips, tax forms, invoices, and more.
• Supported Formats: PDFs, Word docs, CSVs, images, schematics, and even handwritten notes.

• Business Domain Expertise: Finance, legal, logistics, insurance, healthcare, human resources, and general business operations.
To deliver accurate outputs, Kudra provides users with a flexible workflow builder to customize document processing sequences. Users can choose from multiple advanced OCR engines to handle tables, schematics, handwritten notes, and complex layouts.

Post information extraction, data can be seamlessly exported to various endpoints like Dropbox, QuickBooks, Google Sheets, internal databases, and more for further analytics.

What truly sets Kudra apart is how it amplifies human capabilities through its AI. The ChatGPT module allows users to leverage conversational AI to analyze documents and prompt complex information extraction beyond rules-based identification.
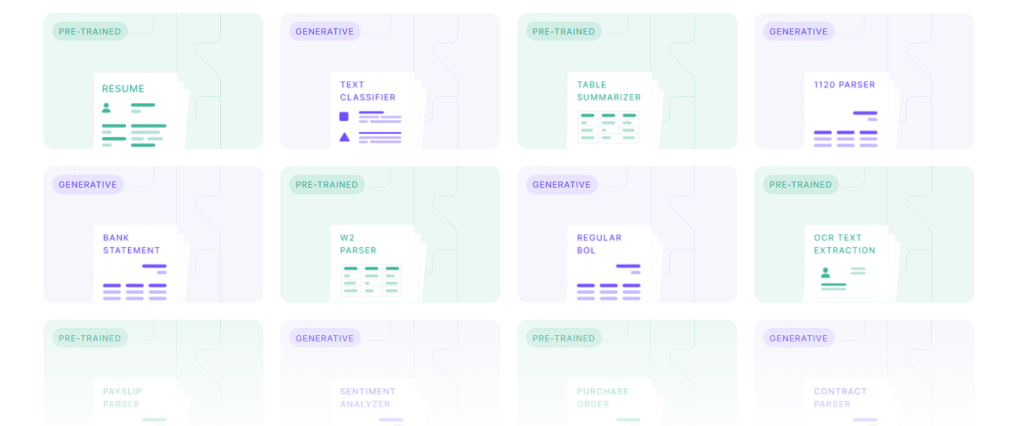
The platform also has over 20 pre-trained AI templates tailored to documents like W2 tax forms, vehicle insurance claims, bank statements, invoices, and more across finance, legal, logistics, and other domains. This enables easy customization for common business use cases.

The platform also has over 20 pre-trained AI templates tailored to documents like W2 tax forms, vehicle insurance claims, bank statements, invoices, and more across finance, legal, logistics, and other domains. This enables easy customization for common business use cases.
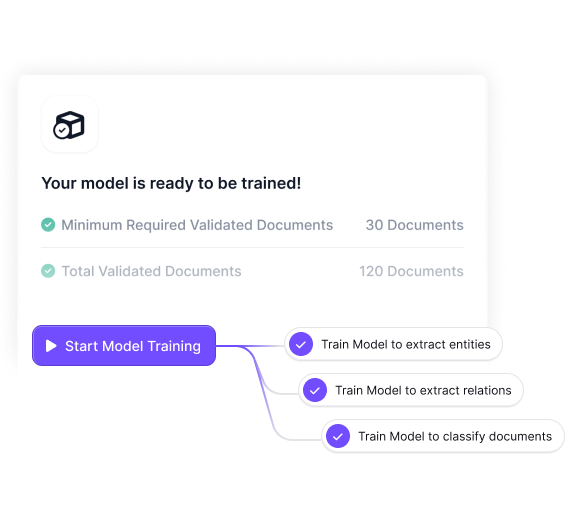
Finally, Kudra facilitates training custom AI models on specialized data extraction tasks where generic models underperform. With as few as 20 labeled examples, the platform can develop models that reach over 90% accuracy on specialized tasks.
For instance, a construction company can train an AI model to parse technical drawings and schematics to extract measurements, materials specifications, and cost data with a high degree of accuracy.
The Power of Kudra in Logistics’ Document Extraction
Logistics teams deal with high document variety from structured shipping manifests to intricate bills of lading and comprehensive logistics reports. Manual data extraction is tedious and risk-prone.
Kudra empowers logistics companies to automatically extract essential data like:
– Shipment details: weight, dimensions, handling requirements, addresses, etc.
– Tracking numbers and statuses across transport legs
– Customs documentation & clearances
– Delivery timestamps & proof of fulfillment
– Damage, delays, exceptions and corrective measures
– Carrier and transport mode analytics
This provides stakeholders with real-time visibility on shipment routes, enabling dynamic rerouting, ETAs, and proactive issue resolution. Overall, Kudra drives significant efficiency gains in logistics document processing.
Benefits of Automated Document Extraction
Solutions like Kudra usher in the next evolution of intelligent data extraction. Converting unstructured documents into machine-readable formats unlocks tremendous potential.
The key advantages include:
– Increased Efficiency: Automation ensures reliable, 24/7 data extraction without manual intervention, reducing costs and errors. This accelerates downstream processes.
– Improved Accuracy: AI techniques like natural language processing ensure a nuanced understanding of documents, boosting data accuracy over manual entry.
– Cost Savings: Automation reduces the headcount required for data entry. Efficient processes also prevent losses from incorrect data.
– Better Compliance: Accurate, real-time data aids compliance with regulations and contractual obligations through detailed audit trails.
– Scalability: With automation, document processing can scale rapidly to handle fluctuations and growth without proportional cost increases.
– Boosted Productivity: Skilled knowledge workers can focus on high-value analytical tasks by eliminating slow, repetitive data entry.
With a capable platform like Kudra, the data and insights locked within unstructured documents become easily accessible to create outsized business value.
The Future of Document Extraction
While AI-driven data extraction brings massive improvements, the unstructured data challenge is far from solved. Formats will continue evolving, and documents will grow more complex.
Ongoing efforts to convert unstructured data like scanned images to structured digital formats through techniques like AI-based data labeling, metadata tagging, and format standardization will persist.
However, the diversity of document types and the contextual, free-flowing nature of information means technology must progress beyond reliance on structured data.
This underscores the need for advanced extraction solutions like Kudra that combine automation with adaptable AI techniques for sustainable, scalable performance now and in the future.
Conclusion
Documents contain nuggets of essential business data trapped within unstructured formats. Manual data extraction is slow, expensive, and inaccurate. AI-driven intelligent document processing solutions like Kudra enable easy setup of automated workflows with top-notch accuracy.
Kudra empowers users with features like flexible workflow builders, pre-trained AI, and the ability to customize AI models. It drives efficiency by extracting actionable data from contracts, shipping manifests, financial statements, invoices, and more. The performance improvements stretch across domains like finance, legal, logistics, and healthcare.
As businesses pursue data-driven growth, unlocking insights from unstructured documents is key to success. With Kudra, teams can tap into a wealth of previously hidden data to gain unprecedented visibility and intelligent decision-making capabilities based on accurate, real-time information. The time to process documents smarter is now. Empower your business with Kudra.