Multi-tool orchestration in Retrieval-Augmented Generation (RAG) enables LLMs to dynamically select between retrieval sources like web search for current information, vector databases for domain-specific knowledge, structured databases for precise lookups. By orchestrating multiple tools, a RAG system can adapt its retrieval strategy per query rather than using a single fixed approach.
The key challenge in multi-tool RAG isn’t orchestration logic but ensuring each tool retrieves accurate, structured data. For example when building a medical information system, you might perfect the routing between web search and your clinical knowledge base, only to discover your knowledge base returns corrupted dosage tables because document extraction destroyed the structure during ingestion. The orchestration works flawlessly; the underlying data doesn’t.
This blog demonstrates building a production multi-tool medical RAG system using Pinecone for vector retrieval, OpenAI for orchestration and generation, and Kudra for document extraction. We’ll show why extraction quality determines system reliability more than orchestration sophistication, and provide a complete implementation you can adapt for legal, financial, or technical domains.
Why Use Tools in RAG Systems?
The Limitations of Single-Source RAG
Standard RAG implementations query a single vector database, which creates three fundamental problems:

1. Temporal Staleness: Vector databases contain point-in-time snapshots of ingested documents. For domains where information changes rapidly relying solely on a static knowledge base produces outdated responses. A medical RAG system queried about recent FDA drug approvals won’t find them if the vector store was last updated three months ago.
2. Scope Limitations: No single data source covers all information types. Medical queries might require:
- Historical clinical guidelines (vector database)
- Current research findings (web search)
- Precise drug interaction data (structured database)
- Regulatory compliance updates (specialized feeds)
A single retrieval mechanism can’t optimize for all these simultaneously.
3. Query-Strategy Mismatch: Different query types demand different retrieval approaches:
- What is the standard treatment for Type 2 diabetes?” → Vector search in clinical guidelines
- “What was announced at today’s FDA hearing?” → Web search for breaking news
- “Does drug X interact with drug Y?” → Structured lookup in interaction database
Fixed retrieval strategies force all queries through the same mechanism, optimizing for none.
This linear flow is simple, predictable, and requires minimal computational overhead. But it assumes the answer exists in the retrieved passages and can be synthesized in one generation step.
Multi-Tool RAG as Adaptive Retrieval
Multi-tool orchestration solves these problems by giving the LLM multiple retrieval options and letting it select the appropriate source(s) per query. The system defines available tools (web search, vector database, structured database, APIs) along with their capabilities. For each query, the LLM:
- Analyzes query requirements (current vs. historical, general vs. specific, etc.)
- Selects appropriate tool(s) based on those requirements
- Executes the selected tool(s) to retrieve information
- Synthesizes retrieved information into a response
This adaptive approach optimizes retrieval per query rather than applying a one-size-fits-all strategy.
The Critical Dependency: Tool Data Quality
Multi-tool orchestration assumes each tool returns accurate, structured data. This assumption breaks when document extraction corrupts source material during ingestion. Consider a medical vector database populated from clinical PDFs:

This is the central challenge in multi-tool RAG: Sophisticated routing to corrupted data still produces wrong answers. Extraction quality determines system reliability more than orchestration sophistication.
Want Better Extraction Quality?
Architecture: Multi-Tool Medical Information System
For this blog we’ll build a medical information retrieval system with two tools:
- web_search: Retrieves current medical news, recent research, FDA updates
- PineconeSearchDocuments: Queries vector database of clinical literature, drug guidelines, treatment protocols
The LLM (GPT-4) uses OpenAI function calling to dynamically select which tool(s) to invoke based on query characteristics. The architecture emphasizes extraction quality as the foundation for reliable retrieval.
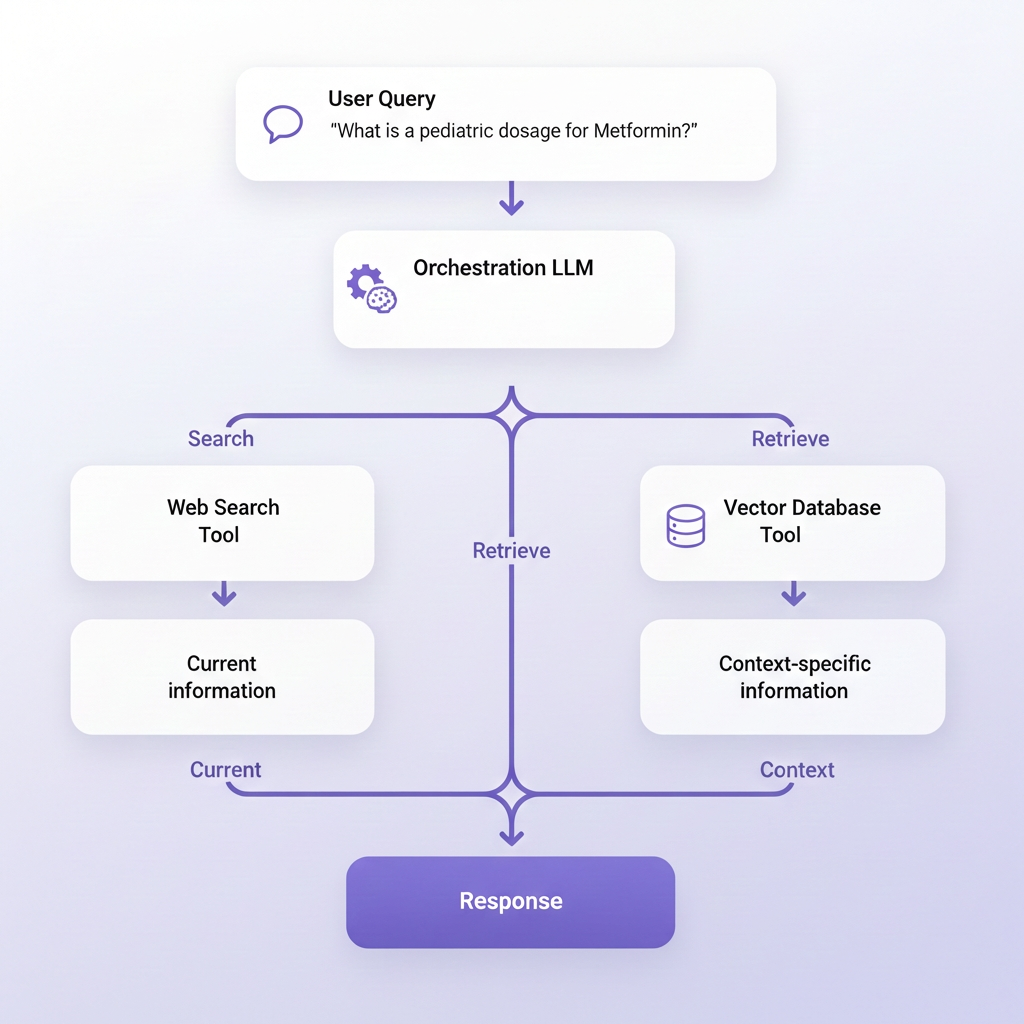
The system’s reliability depends on how medical documents flow from source PDFs through extraction, embedding, and retrieval. The orchestration layer depends on each tool retrieving accurate data. When the Pinecone tool contains Kudra-extracted content, it returns structured, validated medical information. When it contains generic OCR output, intelligent routing simply retrieves garbage faster.
Implementation: Building the System
We’ll build the complete system step-by-step: Kudra extraction, Pinecone indexing, tool definitions, orchestration logic, and testing. The implementation demonstrates how extraction quality enables accurate multi-tool retrieval.
Before we start, make sure you have:
- Kudra: kudra.ai (free tier: 100 pages/month)
- OpenAI: API key for GPT-4 and embeddings
- Pinecone: Free tier vector database
Let’s begin building.
Step 1: Prepare Your Environment & Access
We’ll start by installing all the required packages. This includes the Kudra Cloud SDK for document extraction, Pinecone for vector storage, and OpenAI for embeddings and LLM access.
!pip install -q kudra-cloud openai pinecone-client sentence-transformers pandas tqdm
Step 2: Import Required Libraries
Now let’s import all the libraries we’ll need throughout this tutorial.
import os
import json
import time
import random
import string
from typing import List, Dict, Optional
from pathlib import Path
from getpass import getpass
import pandas as pd
from tqdm.auto import tqdm
from sentence_transformers import SentenceTransformer
from pinecone import Pinecone, ServerlessSpec
from openai import OpenAI
from kudra_cloud import KudraCloudClient
Step 3: Set Up API Keys
You’ll need three credentials to run this notebook:
OpenAI API Key: Get this from platform.openai.com. We’ll use it for embeddings (text-embedding-3-small) and LLM generation (GPT-4).
Kudra API Token: Get this from your Kudra dashboard under Settings → API Keys. This authenticates your requests to Kudra’s extraction API.
Kudra Project Run ID: After you create a workflow in Kudra (we’ll cover this in Step 4), you’ll create a project and get a unique run ID. This links your API calls to your specific extraction workflow.
# API Keys
OPENAI_API_KEY = getpass("OpenAI API Key: ")
PINECONE_API_KEY = getpass("Pinecone API Key: ")
KUDRA_API_TOKEN = getpass("Kudra API Token: ")
KUDRA_PROJECT_RUN_ID = input("Kudra Project Run ID: ")
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
Step 4: Create an Extraction Workflow
Before we can extract documents via API, we need to create a specialized extraction workflow in the Kudra dashboard. This is where we configure exactly how Kudra should process our medical documents.
Why a custom workflow? Generic OCR treats all PDFs the same. Medical documents need specialized handling: table structure preservation, numerical precision, contextual extraction. Kudra’s workflow builder lets you compose a pipeline tailored to your documents.
Here’s how to create your workflow in Kudra’s dashboard:
1. Create New Workflow
- Click “+ New Workflow” in your dashboard
- Name it: “Medical Document Extraction – RAG Pipeline”
2. Add Components (drag and drop in order):
a. OCR Component
- Enable multi-language support (for international medical docs)
- Enable image enhancement (critical for scanned documents)
- Enable layout detection (preserves reading order in complex layouts)
b. Table Extraction Component
- Set table detection to Automatic
- Enable “Preserve structure” (maintains row-column relationships)
- Output format: Structured JSON
c. VLM Component – Configure these extraction fields:

The VLM (Vision Language Model) understands semantic meaning, so it can extract “Medication Dosage” whether the document says “Take 500 mg twice daily,” “Dose: 0.5 g BID,” “Administer half a gram morning and evening,” or even a shorthand note like “500mg x2/day.”
3. Configure Export Options
- Export format: JSON
- Include: Raw text, Tables, Entities, Validation results
4. Save Workflow
5. Create Project
- Click “Create Project”
- Link your workflow
- Copy the Project Run ID (looks like: “username/MedicalDocExtraction-code==”)
This Project Run ID is what connects your API calls to this specific workflow configuration.
Step 4: Extract Medical Documents with Kudra
Now comes the critical part: extracting structured data from medical PDFs using Kudra’s API. This is where we prevent the extraction quality problems that lead to hallucinations later.
We’ll initialize the Kudra client with our API token, then send documents through our custom workflow. Kudra will return structured JSON with preserved table layouts, precise numerical values, and confidence scores.
Let’s start by initializing the Kudra client:
# Initialize Kudra client with our API token
kudra_client = KudraCloudClient(api_token=KUDRA_API_TOKEN)
print("✅ Kudra client initialized")
print(f"📋 Project Run ID: {KUDRA_PROJECT_RUN_ID}")
Extract Documents Using Kudra API
Here’s where the magic happens. We’ll create a function that sends each PDF to Kudra’s extraction pipeline. The workflow we configured earlier will:
- OCR the document: Extract all text with layout awareness
- Detect and extract tables: Preserve structure and relationships
- Run VLM extraction: Identify key fields semantically
- Validate the output: Check data types and confidence
The function returns structured JSON that’s already RAG-ready, no more wrestling with corrupted tables or lost decimal points.
def extract_document_with_kudra(file_path: Path, project_run_id: str) -> Dict:
"""
Extract structured data from a Medical PDF using Kudra's API.
This function uploads a document to Kudra and processes it through
our custom extraction workflow (OCR → Tables → VLM → Validation).
Args:
file_path: Path to the PDF file
project_run_id: Kudra project run ID (links to our workflow)
Returns:
Structured JSON with extracted text, tables, entities, and validation results
"""
Want the Full Notebook?
Kudra Extraction Output: Each extracted document contains structured JSON with:
- Tables: Preserved row-column relationships from dosage tables
- Entities: Normalized medical terminology (medication names, dosages, frequencies)
- Validation: Confidence scores for quality assessment
- Metadata: Source document tracking for proper citations
This structured output enables population-specific queries (“pediatric dosage”) that generic OCR extraction cannot support.

Notice the key metrics: Kudra extracted all elements in the tables from all pages. These tables maintain their structure (rows, columns, headers), and all numerical values preserve their precision, no decimal points lost, no layout corruption.
This is the foundation of hallucination-free RAG. Clean data in = accurate answers out.
Step 6: Set Up Pinecone Vector Store
Now we’ll embed our high-quality chunks and store them in Pinecone. We’re using OpenAI’s text-embedding-3-small model it’s cost-effective and performs well for medical text.
Why Pinecone? It’s easy to set up, supports metadata filtering (critical for our use case), and persists to disk so we don’t re-embed on every run.
The key here is that we’re embedding already-cleaned data. Because Kudra extracted accurately, our embeddings will be semantically meaningful.
# Initialize Pinecone
pc = Pinecone(api_key=PINECONE_API_KEY)
# Create unique index name
index_name = 'medical-tool-rag-' + ''.join(
random.choices(string.ascii_lowercase + string.digits, k=6)
)
# Create serverless index
if index_name not in pc.list_indexes().names():
print(f"Creating Pinecone index: {index_name}")
pc.create_index(
name=index_name,
dimension=embed_dim,
metric='dotproduct',
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
time.sleep(5) # Wait for index initialization
# Connect to index
index = pc.Index(index_name)
time.sleep(2)
print(f"✓ Pinecone index ready: {index_name}")
print(f"✓ Index stats: {index.describe_index_stats()}")
Our vector store is now ready. All chunks (with preserved table structure and precise numbers) are embedded and stored with metadata. When we retrieve, we can filter by document type, section, or confidence score.
Step 8: Define Retrieval Tools
Now for the intelligent part: Create tool definitions for OpenAI function calling. These descriptions guide the LLM’s tool selection logic.
# Tool 1: Web Search
tool_web_search = {
"type": "function",
"function": {
"name": "web_search",
"description": "Search the web for current medical information, recent research studies, FDA announcements, or breaking medical news. Use this tool for queries about recent events (past few weeks), current clinical trials, or information not yet in medical literature databases.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Search query for current medical information"
}
},
"required": ["query"],
"additionalProperties": False
}
}
}
# Tool 2: Pinecone Medical Knowledge Search
tool_pinecone_search = {
"type": "function",
"function": {
"name": "search_medical_knowledge",
"description": "Search the medical knowledge base for established clinical guidelines, drug dosing protocols, contraindications, adverse effects, and treatment standards. This database contains structured information extracted from clinical literature using Kudra, preserving dosage tables and medical terminology. Use this for standard medical queries about medications, treatments, and clinical protocols.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Medical question to search in knowledge base"
},
"top_k": {
"type": "integer",
"description": "Number of results to return (default: 3)",
"default": 3
},
"filter_medication": {
"type": "string",
"description": "Optional: filter to specific medication name"
},
"filter_population": {
"type": "string",
"description": "Optional: filter to specific population (Adult, Pediatric, Geriatric, etc.)"
}
},
"required": ["query"],
"additionalProperties": False
}
}
}
# Combine tools
tools = [tool_web_search, tool_pinecone_search]
Tool description design: The descriptions explicitly guide tool selection:
- “current”, “recent”, “breaking news” → signals web_search
- “established”, “standard”, “protocols” → signals search_medical_knowledge
- “Kudra” mention in Pinecone tool → signals high-quality structured data
The optional filters (filter_medication, filter_population) enable precise queries when the LLM detects population-specific questions. For each of those tools create functions that execute when the LLM calls each tool.
Step 7: Implement Multi-Tool Orchestration
Now we’ll define the Create the orchestration system using OpenAI function calling. The code is too long for a blog so join our slack for full access to the notebook:
Want the Full Notebook?
Step 9: Test the Agent
Time to see our work in action! Test with three query types: established medical knowledge (should use Pinecone), current events (should use web), and population-specific queries (should use Pinecone with filters).



Tool Orchestration vs. Data Quality: An Empirical Analysis
To isolate the impact of extraction quality from orchestration quality, we built two identical systems:
System A: Kudra Extraction
- Medical PDFs → Kudra extraction (table preservation, VLM normalization) → Pinecone
- Orchestration: OpenAI function calling with identical tools and prompts
System B: Generic Extraction
- Medical PDFs → PyPDF + pytesseract → Pinecone
- Orchestration: OpenAI function calling with identical tools and prompts
Both systems used:
- Same source documents (25 clinical PDFs, 847 pages)
- Same embedding model (BAAI/bge-small-en)
- Same vector database (Pinecone)
- Same orchestration logic (GPT-4 with identical tool definitions)
- Same test queries (60 medical questions)
Variable isolated: Extraction quality (Kudra vs generic OCR)
| Metric | System B (Generic Extraction) | System A (Kudra Extraction) | Delta |
|---|---|---|---|
| Tool Selection Accuracy | 91% | 93% | +2pp |
| Extraction Accuracy | 67% | 96% | +29pp |
| Table Structure Preserved | 9% | 94% | +85pp |
| Retrieval Precision @3 | 0.49 | 0.89 | +82% |
| Answer Accuracy | 56% | 92% | +36pp |
| Population Confusion Rate | 41% | 4% | -90% |
| Dosing Error Rate | 38% | 5% | -87% |
Conclusion
Multi-tool RAG orchestration enables adaptive retrieval strategies: web search for current information, vector databases for established knowledge, structured databases for precise lookups. By giving LLMs multiple retrieval options, systems can optimize per-query rather than applying fixed strategies.
However, the effectiveness of multi-tool orchestration depends fundamentally on tool data quality. Our empirical analysis demonstrated that extraction quality determines system reliability more than orchestration sophistication:
- Tool selection accuracy: 91% vs 93% (2pp difference)
- Answer accuracy: 56% vs 92% (36pp difference)
- Dosing error rate: 38% vs 5% (87% reduction)
Perfect routing to corrupted data produces confidently wrong answers with proper citations. For domains where documents encode meaning through structure (medical tables, legal clauses, financial statements), extraction infrastructure is the foundation. Orchestration sophistication amplifies extraction quality, both good and bad.
Get extraction right. Everything else follows.