The difference between a RAG system that users trust and one they second-guess lies in whether it hallucinates despite having the correct documents.
Retrieval-Augmented Generation promised to solve the hallucination problem by grounding LLMs in actual documents. The architecture is straightforward: break documents into chunks, convert them to vectors, retrieve the most similar pieces when users query, and generate answers from that context.
But here’s the uncomfortable reality most production teams discover after deployment:
The system still hallucinates. Not constantly, but enough to erode trust.
The queries work. The retrieval runs. The generation happens. But the quality stays stuck at “mediocre.”
Trace these issues back, and you’ll find the same root cause: how the documents were chunked.
This article dissects why fixed-size chunking creates accuracy problems that no amount of embedding model tuning can fix, and demonstrates how two architectural changes (semantic chunking and LLM-driven metadata enrichment) transform RAG precision from 70% to 90%+ in production deployments.
How Standard RAG Pipelines Handle Documents
The standard RAG architecture was designed specifically to eliminate hallucinations:
- Ingest documents and chunk them into retrievable segments
- Embed chunks into vectors representing semantic meaning
- Retrieve top-K relevant chunks when a user queries
- Ground the LLM’s generation in the retrieved context
- Generate an answer based only on the provided documents
The idea is if the LLM has the facts in front of it, it can’t hallucinate because there’s no need to guess or rely on potentially outdated training data.
RAG does reduce hallucinations by about 42-68% compared to vanilla LLMs, but it doesn’t eliminate them. Recent research on legal RAG systems found that hallucinations remain substantial, wide-ranging, and potentially insidious even when documents are correctly retrieved.
Why Rigid Token Chunking Breaks Retrieval Systems

Rigid, fixed-length chunking slices documents purely by character or token count, ignoring meaning, structure, and intent. The system doesn’t “see” paragraphs, sections, or tables, it just cuts at predefined intervals. That mechanical approach introduces several structural weaknesses:
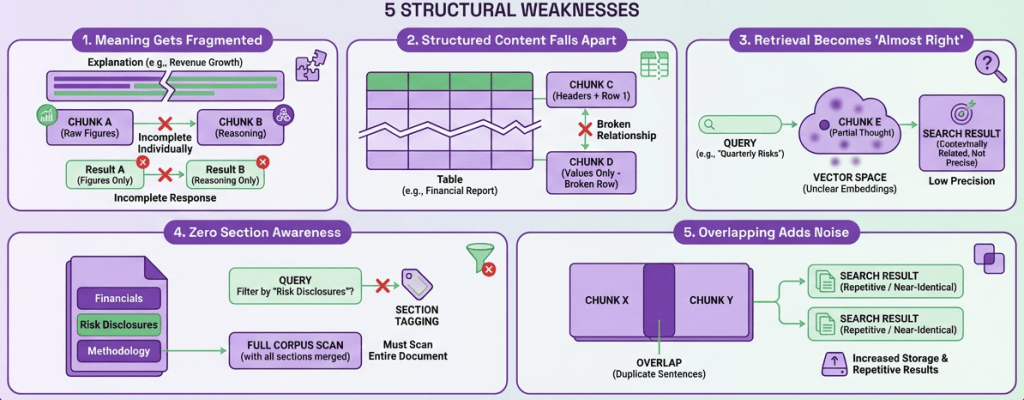
1. Meaning Gets Fragmented: A single explanation can be split into two separate chunks. One piece may contain the raw figures, while the other holds the reasoning behind them. Individually, neither chunk fully answers a query, so retrieval produces incomplete responses.
2. Structured Content Falls Apart: Many documents rely heavily on tables. When chunking cuts through rows, headers get detached from their corresponding values. Once the structural relationship is lost, the extracted data becomes unreliable and often unusable.
3. Retrieval Becomes “Almost Right”: When chunks represent partial thoughts instead of coherent units, their embeddings lose clarity. As a result, similarity search tends to surface content that is near the answer (contextually related but not directly responsive) lowering precision.
4. Zero Section Awareness: Need content only from a specific quarter or a defined section like risk disclosures? With flat chunking, there’s no structural tagging to enable that. Every query must scan the entire corpus through vector similarity alone, without intelligent filtering.
5. Overlapping Adds Noise: To reduce fragmentation, teams introduce overlap between chunks. But this duplicates sentences across multiple segments, increasing storage demands and causing retrieval systems to return repetitive or near-identical results.
These failure modes don’t occur in isolation. A typical hallucination in a production RAG system results from multiple failures stacking.
Want More Information?
Semantic Chunking: Split Where Meaning Changes
Instead of splitting at arbitrary character positions, semantic chunking identifies where topics shift and creates boundaries at those natural transition points. Each chunk becomes a coherent unit of meaning (a complete table, a full argument, an entire explanation) not a fragment defined by token count.
Method 1: Embedding Similarity for Boundary Detection
This approach uses the embedding model itself to find topic transitions:
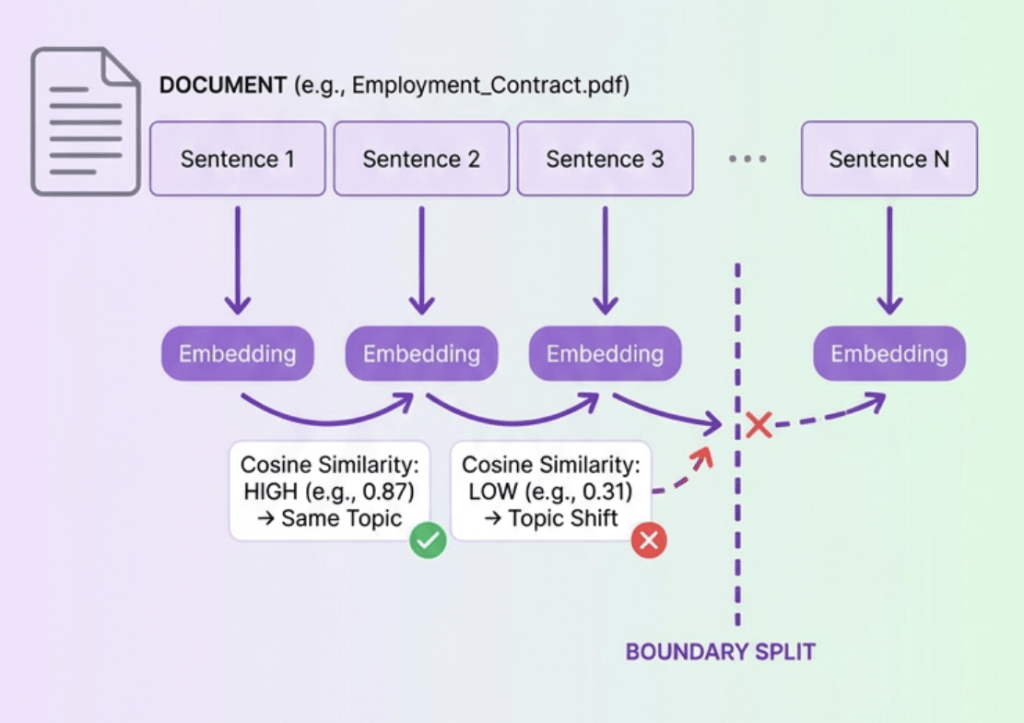
The Process is very simple:
- Segment document into individual sentences
- Generate embeddings for each sentence
- Calculate cosine similarity between consecutive sentences
- Identify sharp similarity drops (topic boundaries: Here you can use diffrent threshold strategies)
- Create chunks at those boundary points
This results in variable-size chunks. Some might be 180 tokens (a brief note). Others might be 2,400 tokens (an extensive analysis section). But each represents a complete semantic unit. A 2025 comparative study found semantic chunking achieves 2-3 percentage point better recall than recursive character splitters, with LLM-enhanced variants reaching 0.919 recall (91.9% accuracy).
Method 2: LLM-Driven Structural Analysis
For higher accuracy at higher cost, use an LLM to understand document structure and decide split points:
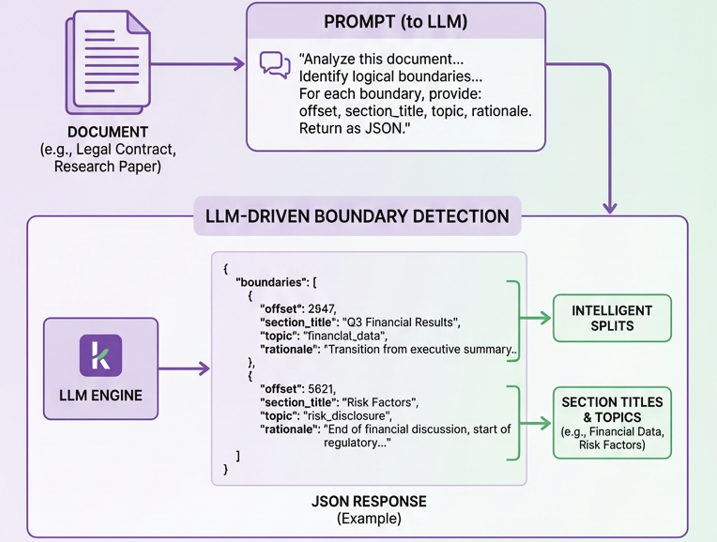
An LLM outperform embedding similarity because it recognizes that:
- A paragraph is a conclusion to the previous section (keep together), not the start of a new topic (don’t split)
- A table and its introductory paragraph should stay together even if the table uses different language
- A footnote refers back to earlier content and should be grouped with what it references

Best use cases: Legal contracts, research papers, technical specifications, compliance documents where structure is critical and budget allows for LLM processing costs.
Method 3: Agentic Chunking with Proposition Extraction
The most sophisticated approach transforms sentences into self-contained propositions before chunking:

Every sentence in every chunk makes sense independently. No pronouns without referents. No “the aforementioned factors” without stating what the factors are. This dramatically improves retrieval quality because each chunk is self-explanatory. The LLM doesn’t need to infer context from surrounding chunks.
Metadata Enrichment: The Filtering Layer RAG Systems Need
Semantic chunking solves the boundary problem. But there’s a second, equally critical issue: finding the right chunks among thousands.
Vector similarity search operates in a single dimension: semantic closeness. It can’t filter by:
- Time period (Q3 2025 vs Q4 2024)
- Document type (annual report vs earnings call)
- Section category (financial data vs risk factors)
- Entity mentions (Company A vs Company B)
Without these filters, every query searches the entire corpus. A question about “Q3 2025 revenue” retrieves chunks from Q3 2023 that happen to mention revenue.
LLM-Powered Metadata Generation
After chunking (semantically or otherwise), pass each chunk through an LLM to extract structured metadata:

Instead of treating a chunk as just a blob of text with an embedding, you pass it through an LLM (or a structured extraction pipeline) to generate explicit, structured attributes. This way the chunk is no longer just a vector in high-dimensional space. It becomes a structured object with filterable dimensions.
That metadata lives alongside the embedding in your vector database. Systems like Pinecone, Weaviate, and Qdrant allow you to apply metadata filters before performing similarity search. This changes retrieval from a probabilistic guess over the entire corpus to a constrained search within a logically relevant subset.
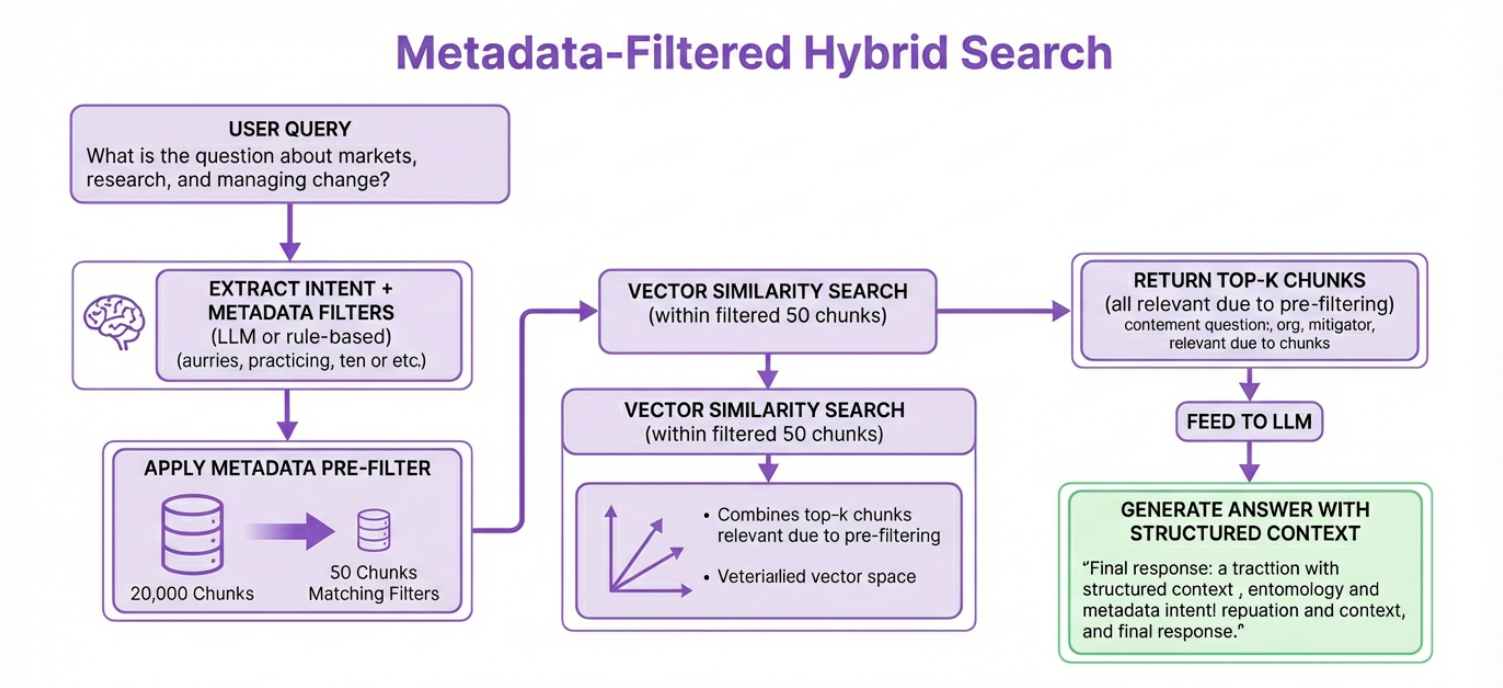
Instead of searching 20,000 chunks and hoping semantic similarity ranks the correct one high enough, you might first filter:
document_type = “10-Q”
time_period = “Q3 2025”
section = “financial results”
Now maybe only 47 chunks remain. Then vector similarity runs on those 47. Every candidate is already contextually valid. You’ve reduced noise before the model even starts ranking. This dramatically improves precision because vector similarity is powerful but not selective. It understands meaning, but it does not understand constraints.
The metadata-enriched retrival workflow follows this pipeline:

It becomes a two-stage system:
Interpret the query structurally: An LLM (or rules engine) parses the user question and extracts filterable dimensions, time ranges, document types, entities, metric names.
Apply hard filters first: Use metadata to narrow the search space to logically valid candidates.
Run vector similarity inside that narrowed subset: Now embeddings are ranking among relevant peers, not the entire universe of chunks.
This is the difference between searching a library by “which books feel similar” versus first going to the correct section, year, and category and then browsing within that shelf.
Metadata enrichment doesn’t replace embeddings. It disciplines them.
And in production systems that discipline is often what pushes retrieval accuracy from “almost right” to consistently correct.
Try Building Metadata Enriched RAG with Kudra
Final Thoughts
Fixed-size chunking was never meant to be the final answer, it was the easiest starting point. And for teams building their first RAG prototype, it serves that purpose.
But production systems serving real users with accuracy expectations can’t stay at “chunk it into 500 tokens and hope for the best.”
The gap between 72% precision (fixed chunks) and 89% precision (semantic + metadata) isn’t incremental. It’s the difference between:
- Answers that are “sort of related” vs answers that are correct
- Users double-checking everything vs users trusting the system
- Retrieval returning adjacent context vs returning the exact right context
- Queries searching 20,000 chunks vs 50 pre-filtered relevant chunks
Modern RAG architectures demand:
Semantic chunking : Split documents where meaning changes, not where token count hits a limit. Each chunk becomes a coherent semantic unit that embeddings can accurately represent.
Metadata enrichment : Extract structured attributes (time period, document type, entities, metrics) that enable precise pre-filtering before vector search. Transform retrieval from “search everything by similarity” to “filter to relevant subset, then search.”
Strategy per document type : Recognize that financial tables need different chunking than legal contracts. Route documents to appropriate processing pipelines based on their structure.
The investment in smarter chunking pays for itself in fewer hallucinations, faster retrieval, higher user trust, and systems that scale without accuracy degrading.
Start with semantic chunking. Add metadata extraction. Measure precision improvement. Watch retrieval transform from “close enough” to “exactly right.”