
Resume parsing, or CV parsing, is the automated process of extracting relevant information from resumes and curricula vitae using technology. This technology utilizes specialized algorithms to identify, extract, and organize key data points about candidates from their resumes, including skills, education, past positions held, and more.
The importance of resume parsing is immense in modern recruitment, enabling efficiency, accuracy, and data-driven hiring decisions. Manual review of resumes is hugely time- and labor-intensive, while automated parsing greatly accelerates screening and surfaces top talent faster. The latest parsing tools also extract data with over 90% accuracy, minimizing human error. Further, the extracted dataset fuels data-driven insights into talent availability, salary benchmarks, and other metrics that optimize hiring
Types of Resume Parsing Software Methods
There are a few core technical approaches to developing resume parsing tools:
Statistical Parsing
Statistical parsers use machine learning algorithms trained on large resume datasets. By analyzing patterns in resume layouts, language use, and key data points, these AI models reliably extract information from new resumes. A major benefit is the hands-off automation and continual improvement with more data. However, extensive resume samples are needed for accurate training.
Keyword-Based Parsing
This rule-based approach relies on predefined keywords and data patterns to identify relevant information. For example, keywords like “Bachelor’s Degree” indicate academic credentials. This method is simple to implement but less flexible – unable to handle resume variability.
Grammar-Based Parsing
In this approach, grammars are manually created to define resume structures. Using these grammar rules, data can be extracted. It allows customization for different resume types but demands extensive manual effort in defining accurate grammar.
Each method has particular strengths and limitations regarding flexibility, customization needs, and ease of set-up. The ideal solution combines statistical and grammar-based parsing to achieve both automation and control.
Challenges of Resume Parsing
Despite major advances, resume parsing faces ongoing barriers:
Consistency Across Resume Formats
Resumes come in many styles and formats – from structured tables to free-flowing paragraphs. Identifying common data points across these formats poses a constant challenge. Adaptability to new formats is essential.
Cultural and Linguistic Nuance
Names, educational systems, and conventions in presenting information – all vary enormously across cultures. Tools need extensive customization to handle global resumes. Different languages add further complexity for multi-lingual parsing.
System Integration
Seamlessly integrating parsing tools with existing recruitment platforms like ATS requires technical resources. APIs and compatible data schemas enable easier connectivity.
Data Privacy
Stringent regulations govern applicants’ data, demanding data security, access controls, and compliance from parsing tools. Adherence to GDPR, CCPA, and other policies is mandatory.
Industry-Specific Jargon
Certain terms, acronyms, and conventions within sectors like tech, finance, or healthcare necessitate customization of language processing per industry. Generic algorithms struggle with such niche terminology.
Addressing these barriers is pivotal to unlocking the power of resume parsing across various recruiting needs.
Precision, Speed, and Ease of Use in Resume Parsing
Kudra offers an exemplary intelligent document processing solution, expertly tackling resume parsing challenges through unrivaled precision, speed, and usability.
As an AI platform, Kudra can analyze and extract information from any document type with pinpoint accuracy – contracts, financial statements, invoices, and more. For resumes, it delivers over 90% precision in extracting in-demand data like skills, qualifications, past employers, and titles.
Such precision stems from Kudra’s robust technology stack:
• Advanced OCR accurately parses text, tables, and images

• Customizable statistical and grammar-based AI models handle variability
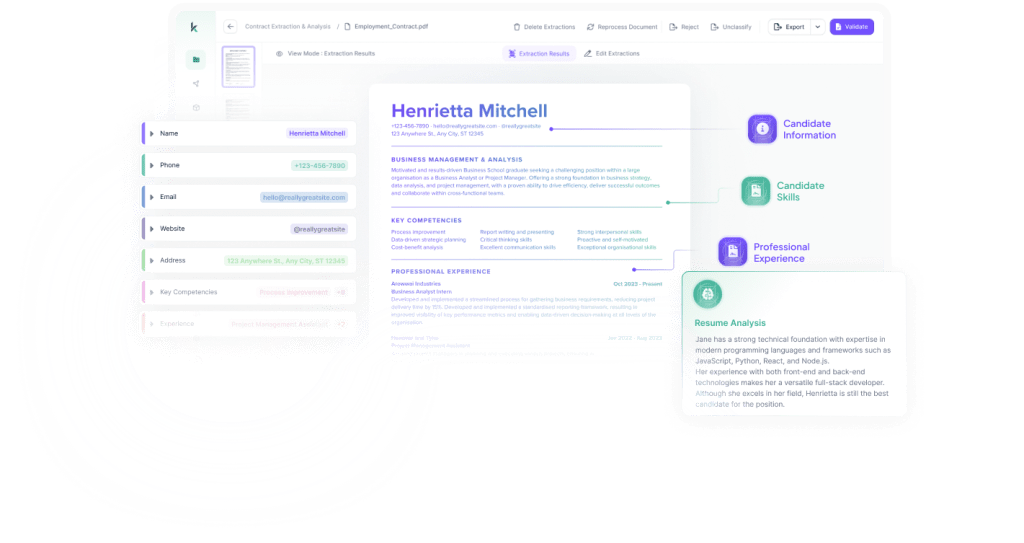
• Integrated ChatGPT module enables text analysis, summarization, and other abstract parsing tasks

Together, these capabilities allow accurate extraction from diverse resume layouts, styles, and content.
Additionally, intelligent workflows and automation ensure high-volume resume parsing at incredible speeds. Recruiters can process hundreds of resumes daily instead of manual weeks-long reviews.
Finally, Kudra’s visual workflow builder removes complexity for users. Without coding, customizable resume parsing pipelines can be set up through simple drag-and-drop interfaces. Pre-built AI templates further simplify extraction for common use cases like skills identification.

This combination of precision, speed, and usability is unmatched among resume parsing solutions, fulfilling the most demanding hiring needs while ensuring a positive user experience through intuitive design.
Recommendations for Resume Parsing
To leverage resume parsing tools effectively, key steps for recruiters include:
• Aligning with Recruitment Needs
Clarify must-have capabilities like language support, data security needs, and integration options during vendor selection. Shortlist tools that best address current and future priorities.
Regular Algorithm Updates
Opt for machine learning-based solutions that continually train their algorithms on fresh resume samples to handle new data patterns better.
Ensuring Data Privacy
Validate vendor security and compliance measures for data protection. Restrict system access to only essential staff and implement usage audits.
Customization for Industry Needs
Create custom parsing models with relevant industry terminology for accurate extraction. For healthcare, train AI on medical codes or equipment names for example.
Cross-Department Collaboration
Involve IT early to smooth system integration with existing infrastructure. Align on data handling protocols between technical and hiring teams.
User Training
Educate recruiters on properly formatting incoming resumes and interpreting parsed output to minimize downstream issues.
Conclusion
Resume parsing is transforming recruiting through enhanced efficiency, precision, and analytics. However, like any technology, it must be strategically implemented to address business challenges, aligned with broader talent acquisition goals beyond just faster screening.
With mounting pressures to hire competitively, organizations must actively explore innovations like intelligent parsing. Solutions like Kudra, with robust data extraction capabilities and easy integration, are primed to deliver immense value. I encourage readers to further explore such technologies’ potential to redefine recruiting operations and unlock smarter, faster hiring.