In 2019, a major European bank expanded into the UAE market. They’d successfully internationalized across 40 countries. They spoke 15 languages. They had robust translation workflows and multilingual customer service.
Arabic was just going to be language number 16.
Six months later, their Middle East operations were hemorrhaging money. Document processing times were 4x longer than any other market. Error rates were through the roof. Compliance was a nightmare.
What went wrong?
Their entire document processing infrastructure was built on assumptions that are true for virtually every other language but catastrophically false for Arabic.
Assumption #1: Text flows left to right

Your OCR system scans a page. It needs to determine reading order. In English, Spanish, French, German, Portuguese (even Chinese and Japanese) there are consistent directionality rules.
Arabic text flows right to left. But numbers in Arabic text flow left to right. And if you’re in insurance, your documents are full of numbers. Policy numbers. Claim amounts. Dates. Phone numbers.
Now add English sections to the same document, switching back to left-to-right.
The system isn’t just translating. It’s constantly trying to figure out which direction it should even be reading. Get it wrong, and you extract “Policy #8742” as “Policy #2478” because the system read the digits backward.
I’ve seen actual claims paid to wrong policy numbers because of this. Not theoretical. Actual money sent to wrong accounts because the OCR reading order got confused.
Assumption #2: Letters look consistent

In Latin alphabets, “a” is “a” whether it’s at the start, middle, or end of a word. Whether it’s alone or connected to other letters.
Arabic doesn’t work this way. Take the letter “ب” (ba). In one word, it might appear as:
- ب (isolated, by itself)
- بـ (initial, at the start)
- ـبـ (medial, in the middle)
- ـب (final, at the end)
Same letter. Four completely different visual forms.
Your OCR system trained on Latin text? It sees these as four different characters. It’s like teaching a system to read English, then discovering that “a” looks entirely different depending on what letters surround it.
Now multiply this by the 28 letters in the Arabic alphabet, each with its own contextual forms.
Assumption #3: Small marks don’t change meaning
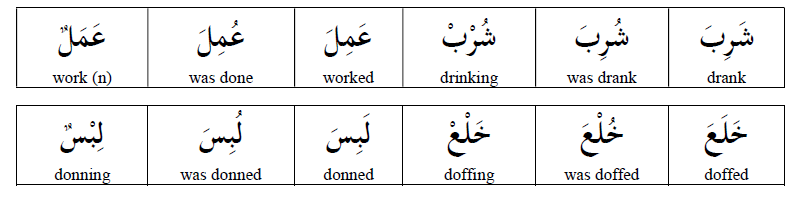
In English, accents matter (naïve vs naive) but you can usually figure out meaning from context.
In Arabic, diacritical marks (tiny symbols above or below letters) completely transform meaning.
Look at these three words. Same base letters. Different diacritics:
- كَتَبَ (kataba) = “he wrote”
- كُتِبَ (kutiba) = “it was written”
- كُتُب (kutub) = “books”
In insurance documents, this isn’t academic. It’s the difference between:
- “The damage was caused by…” (active)
- “The damage was recorded as…” (passive)
- “Damage types include…” (noun)
Get the diacritics wrong or ignore them because your system can’t process them and you’ve extracted fundamentally incorrect information about causation, liability, and coverage.
Assumption #4: Translation is consistent

Most companies think about translation as: Arabic document → English translation → English processing.
But here’s what actually happens in insurance:
A claim comes in. It has an Arabic damage description. An English contractor estimate. An Arabic police report. An English medical assessment. Arabic witness statements. English repair invoices.
You need to:
- Extract information from each (already challenging in mixed formats)
- Translate Arabic portions (now you have everything in English, right?)
- Cross-reference information across documents (wait, does “water damage” in the English estimate match “أضرار المياه” in the Arabic report?)
- Validate consistency (are these describing the same incident?)
- Generate report (in which language? Your insurer wants English, but regulations require Arabic)
This isn’t translation. This is multilingual information synthesis and most systems can’t even conceptualize this as a problem to solve.
The Compounding Effect
Here’s what makes this truly insidious: each of these problems alone is manageable. You can work around any single one.
But they compound.
Your OCR can’t determine reading order reliably, so it extracts text with errors. Your translation service receives incorrect text, so it translates errors. Your validation system checks English against English, missing inconsistencies in the original Arabic. Your compliance team generates reports that don’t match the source documents because context was lost three steps ago.
By the time a document reaches a decision-maker, it’s been through so many lossy transformations that nobody’s quite sure what the original actually said.
And in insurance, where precision matters and regulatory scrutiny is intense, this is terrifying.
The Modern Solution (A Multi-Stage AI Pipeline)

The breakthrough in Arabic insurance document extraction comes from abandoning the idea of a single-pass solution. Instead, modern systems use a sophisticated multi-stage pipeline where each stage specializes in a specific aspect of the problem.
Think of it as an assembly line for intelligence, where each stage adds a layer of understanding until what emerges at the end isn’t just text, but structured, validated, semantically-rich data ready for RAG integration.
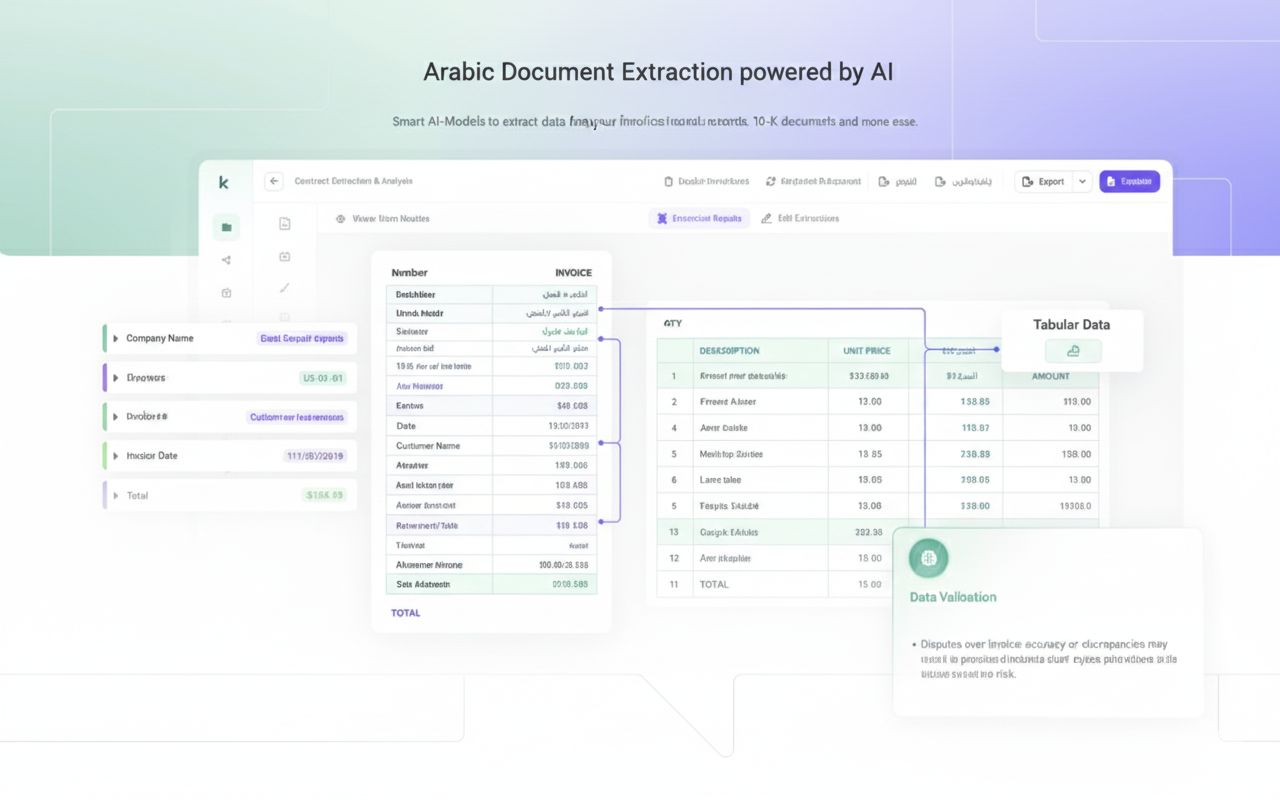
Stage 1: Document Understanding and Layout Analysis

The pipeline begins not with text extraction, but with visual understanding. This is where computer vision models trained on document layouts analyze the PDF image to understand its structure before reading a single character.
Document Classification: The first neural network determines what type of insurance document this is. A motor insurance policy has a different structure from a health insurance claim form, which differs from a reinsurance treaty. Modern vision transformers (ViT) excel at this task, having been trained on millions of document images to recognize patterns in layout, logo placement, and visual structure.
This classification step is crucial because it sets the expectations for everything downstream. Once the system knows it’s looking at a Saudi health insurance policy, it knows to expect specific sections: مستفيد (beneficiary), تغطية (coverage), استثناءات (exclusions). It knows where to look for critical data.
Layout Segmentation: Next comes the sophisticated task of understanding document geometry. Advanced segmentation models (often based on architectures like Mask R-CNN or more recent transformer-based approaches) divide the page into regions: headers, paragraphs, tables, signatures, stamps, logos.
This is where you’d see bounding boxes appear around distinct regions if you were visualizing the process. Each region gets classified: this is a data table, this is a paragraph of terms and conditions, this is a signature block. The model doesn’t just draw rectangles; it understands hierarchical relationships. It knows that this small table is a footnote reference to that larger table above it.
For Arabic documents, this stage must account for right-to-left reading order. The layout model learns that in Arabic insurance forms, the most important information typically appears in the top-right corner, not top-left. Column headers in tables read from right to left. Margin notes appear on the left side of the page.
Table Detection and Structure Recognition: Here’s where things get particularly interesting for tabular data. Specialized table detection models identify table boundaries, then table structure recognition models map out the internal grid.
Modern approaches use graph neural networks to understand table topology. Instead of assuming tables are perfect grids, these models represent tables as graphs where cells are nodes and spatial relationships are edges. This handles merged cells, irregular spacing, and the multi-line cell content common in Arabic insurance documents where verbose coverage descriptions span multiple rows.
The output of this stage is a structured representation: “This document is a Moroccan vehicle insurance policy. It contains three tables: a premium calculation table in the upper right, a coverage details table in the center, and a payment schedule at the bottom. Here are the cell coordinates and hierarchical relationships.”
Stage 2: Arabic-Optimized OCR with Contextual Awareness

Now that we understand where the text is and what role it plays, we can actually read it. This is where specialized Arabic OCR engines enter the pipeline.
Modern Arabic OCR Architecture: The latest Arabic OCR systems use transformer-based architectures that process text bidirectionally. Unlike older systems that tried to segment Arabic letters (an impossible task given their connected nature), modern approaches treat entire words or even phrases as atomic units.
These models have been trained on millions of Arabic text images, learning to recognize not just individual letter forms but contextual variations. The letter ع looks different at the start of a word versus the middle versus the end, and different again when adjacent to certain other letters. Transformer attention mechanisms excel at capturing these dependencies.
For insurance documents specifically, fine-tuned models have learned domain vocabulary. They know that تأمين (insurance), قسط (premium), and مطالبة (claim) are high-frequency terms. When the visual input is ambiguous (poor scan quality, unusual font) the language model component biases toward insurance terminology.
Confidence Scoring and Uncertainty Estimation: Here’s a critical innovation: modern OCR doesn’t just extract text, it estimates confidence for every character, word, and phrase.
When the model encounters a degraded section where a crucial policy number is barely legible, it doesn’t just guess. It outputs: “I’m 94% confident this says ‘POL-2024-7891’ but there’s a 6% chance the ‘7’ is actually a ‘1’.” This uncertainty propagates through the pipeline.
For RAG systems, this is invaluable. Instead of polluting your vector database with potentially incorrect data, you can flag low-confidence extractions for human review or handle them specially in downstream processing.
Stage 3: Table Structure Extraction and Cell Association

With text extracted, we now face the challenge of putting it back together in the right structure. This is where many systems fail, because it’s not enough to know that cell A contains “5000” and cell B contains “تأمين شامل” (comprehensive insurance). You need to know that cell A is in the “المبلغ” (amount) column and cell B is in the “نوع التغطية” (coverage type) column, and they’re both in row 3, which represents the third coverage item.
Spatial Reasoning with Graph Neural Networks: Modern table extraction uses graph neural networks (GNNs) to reason about spatial relationships. Each extracted text region becomes a node, and the GNN learns to classify relationships: “is_left_of,” “is_above,” “is_in_same_row,” “is_in_same_column.”
For Arabic tables, the model has learned that column headers appear at the top of columns (despite right-to-left reading), but row headers typically appear on the right side of rows. It understands that merged cells spanning multiple columns represent summary categories.
The GNN outputs a structured representation:
Row 1: [Header] نوع التأمين | الأساسي | الشامل | ضد الغير
Row 2: [Data] القسط السنوي | ١٢٠٠ ريال | ٣٥٠٠ ريال | ٨٠٠ ريال
Semantic Role Labeling for Table Cells: But structure alone isn’t enough. We need to understand what each cell means. This is where semantic role labeling models, fine-tuned on insurance documentation, classify cell content by type.
The model learns patterns: cells containing patterns like “رقم-٤أرقام-٤أرقام” are likely policy numbers. Cells with currency amounts in specific columns are premiums or coverage limits. Dates in particular formats correspond to policy start/end dates.
This semantic understanding is crucial for RAG integration. When a user later asks “What’s my annual premium for comprehensive coverage?”, the RAG system needs to know which extracted cell contains that information. Semantic labels provide that mapping.
Stage 4: Agentic Validation and Self-Correction
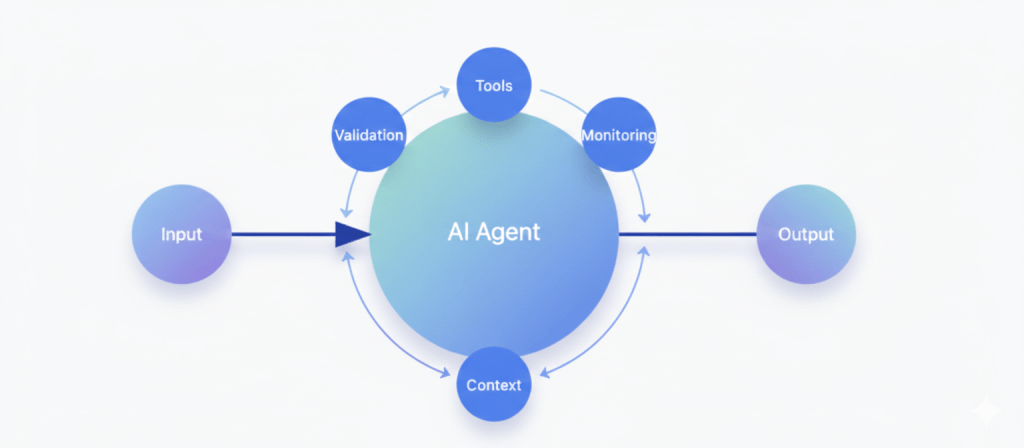
This is where modern document processing moves beyond simple OCR and becomes something much more powerful.
Instead of treating the first extraction as the final truth, advanced systems use AI agents that continuously check, verify, and improve their own results. Think of it as an automated quality-control layer for data.
These agents look at the extracted information from different angles:
Consistency checks
If totals don’t match their line items, or currencies and locations don’t align, the system knows something went wrong.Structure awareness
Insurance documents follow patterns. A car policy should have vehicle details. A health policy should have member and coverage information. If something is missing, the system actively searches the document again to find it.Cross-referencing
Key values like policy numbers or premiums appear multiple times. The system compares them across the document and uses probability and context to decide which version is correct.Contextual reasoning
The AI also understands what makes sense in the real world. If a premium looks unrealistically low for a certain type of coverage, it checks whether the number was misread or labeled incorrectly.
When a problem is detected, the system doesn’t just flag it — it goes back to the original document and re-reads the exact area that caused the issue, using better image processing or a more specialized OCR model.
This creates a smart feedback loop:
extract → validate → re-extract → improve.
After a few passes, the system converges on the most accurate version of the data, with any remaining uncertainties clearly marked. That’s what turns raw document scanning into reliable, production-grade intelligence.
Stage 5: RAG Integration and Query Optimization
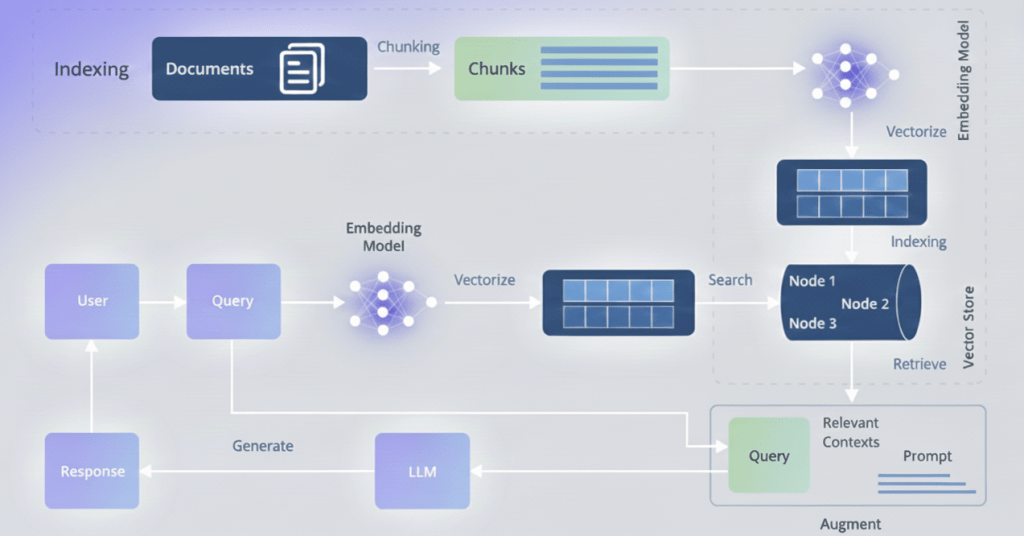
The final stage transforms our clean, validated, semantically-enriched data into a RAG-ready knowledge base that can answer complex insurance queries with unprecedented accuracy.
Hybrid Vector and Graph Storage: Modern RAG systems for insurance don’t rely solely on vector embeddings. They use hybrid architectures that combine:
Vector Store: Embedded representations of text chunks, optimized for semantic similarity search. When a user asks “ما هي تغطية التأمين الصحي للعمليات الجراحية؟” (What is the health insurance coverage for surgical procedures?), vector search retrieves semantically similar content across all policies.
Graph Database: The knowledge graph built in Stage 5, enabling precise relationship traversal. When a user asks “Show me all policies for vehicles owned by Ahmad Ali,” graph queries provide exact answers.
Structured Tables: Original tabular data preserved in relational format for precise numerical queries and aggregations.
The RAG system intelligently routes queries to the appropriate storage backend. Semantic questions go to vectors. Relationship questions go to graphs. Aggregation questions (“What’s the total annual premium across all my policies?”) go to structured tables.
Context-Aware Chunking for Arabic Text: Simply breaking Arabic text into fixed-size chunks destroys meaning. Modern systems use linguistic chunking that respects Arabic phrase boundaries, semantic completeness, and domain-specific structures.
A coverage clause like “تغطي هذه الوثيقة جميع الأضرار المادية للمركبة بما في ذلك الحوادث والسرقة والحريق، مع استثناء الأضرار الناتجة عن القيادة تحت تأثير الكحول أو المخدرات” (This policy covers all material damage to the vehicle including accidents, theft, and fire, excluding damage resulting from driving under the influence of alcohol or drugs) needs to be kept together. Splitting it would separate the coverage from its critical exclusion clause.
The chunking algorithm uses Arabic natural language processing to identify clause boundaries, legal structure markers, and semantic units that must stay together. Each chunk is embedded with surrounding context—the table it came from, the section header, the policy type—so the RAG retrieval preserves that context.
Query Understanding and Expansion: When a user submits a query to the RAG system, it doesn’t go directly to retrieval. First, a query understanding module powered by Arabic language models analyzes the intent.
“كم قسط التأمين؟” (How much is the insurance premium?) is ambiguous. Which policy? Which premium type (annual, monthly)? The query expansion system generates multiple specific queries:
- “ما قيمة القسط السنوي لوثيقة رقم…” (What is the annual premium value for policy number…)
- “ما هي الأقساط الشهرية المطلوبة…” (What are the required monthly installments…)
Each variant is executed, and results are ranked by relevance and confidence. The system might return: “Based on policy POL-2024-7891, your annual premium is 3,500 SAR, payable in quarterly installments of 875 SAR.”
Confidence-Weighted Retrieval: Remember those confidence scores we propagated through the entire pipeline? They pay off here. When the RAG system retrieves information to answer a query, it weights results by extraction confidence.
High-confidence extractions are presented directly: “Your coverage limit is 500,000 SAR.” Low-confidence extractions are hedged: “Based on available data, your coverage limit appears to be 500,000 SAR, though you may want to verify this with your policy document.” Very low-confidence extractions might not be returned at all, with the system instead suggesting: “I don’t have clear information about your coverage limit. Would you like me to help you find this in your policy document?”
This confidence-aware retrieval prevents the RAG system from confidently stating incorrect information—a critical requirement for insurance applications where errors have legal and financial consequences.
The Questions You Should Be Asking
If you’re evaluating solutions for Arabic document processing (whether ours or anyone else’s) here are the questions that actually matter:
“Can it handle our messy real-world documents?”
Test documents should include:
- Mixed Arabic and English in the same document
- Poor-quality scans or photos
- Handwritten Arabic sections
- Tables with mixed-language headers
- Regional dialect variations if you operate across multiple Arabic-speaking countries
If a demo only works on clean, typed, professional documents, it won’t work in production.
“Does it understand context or just translate words?”
Ask it a question that requires connecting information across multiple sections of a document.
“What’s the coverage limit for water damage excluding routine maintenance?” should require understanding:
- Water damage coverage section
- General coverage limits
- Maintenance-related exclusions
- How these three pieces interact
If it can’t do this, it’s just translation with extra steps.
“Can I ask follow-up questions?”
Real understanding means you can have a conversation:
- Initial question: “Is wind damage covered?”
- Follow-up: “What about if the wind damage occurred because windows were left open?”
- Follow-up: “Are there any case precedents in our records where we approved this?”
If the system can’t handle multi-turn questions that build on previous answers, it doesn’t truly understand context.
“What happens when it’s uncertain?”
AI should tell you when it’s not confident about something.
“Based on Section 4, Article 12, water damage appears to be covered, however the Arabic term ‘تسرب’ in the claim description could mean either ‘leak’ or ‘seepage’, which have different coverage implications. Human review recommended.”
Systems that always sound confident are dangerous. Good AI knows what it doesn’t know.
“Can I teach it our specific terminology?”
Every insurance company has internal conventions. Policy codes, specific term definitions, classification systems.
Can the AI learn that when your company says “Category A water damage” you specifically mean damage from clean water sources per your internal classification system, not standard industry categories?
If not, you’ll spend forever translating between AI outputs and your actual business processes.
Your Next Step: See It In Action With Your Own Documents

The insurance industry’s data extraction challenge isn’t going away—it’s growing as document volumes increase. The question isn’t whether to automate, but when to start and who to partner with.
Ready to see what ML-powered extraction can do for your specific documents?
Kudra AI offers a free document assessment: send us 10-20 sample documents (anonymized), and we’ll process them to demonstrate real-world accuracy, speed, and extraction capabilities with your actual content.
No commitment required. Just clear evidence of what’s possible when you unlock the data trapped in your documents.
Contact Kudra AI today to transform manual data extraction into automated intelligence.
Found This Helpful?
Book a free 30-minute discovery call to discuss how we can implement these solutions for your business. No sales pitch, just practical automation ideas tailored to your needs.
Book A Call