
The mailroom of a commercial insurance carrier is a peculiar kind of chaos. Each morning, thousands of documents arrive: hastily scanned incident reports, handwritten medical notes, photocopied police statements, forms filled out in ballpoint pen at kitchen tables. They accumulate in filing cabinets, email inboxes, and on desks, each one a claim waiting to be processed, a worker waiting for benefits, a business waiting for resolution.
For a lot of insurance companies, this chaos had a precise cost: five days from document arrival to claims assignment, 2,700 hours of manual labor annually, and a claims processing backlog that grew faster than any team could manage. The problem wasn’t a lack of effort, it was the fundamental mismatch between human processing speed and document velocity.
But what if that mismatch could be erased? Vision-language models, when properly fine-tuned for domain-specific document understanding, are transforming the impossible into reality: processing speeds 100 times faster, turnaround times cut from five days to one hour, and straight-through processing rates approaching 90%.
You’re about to explore how these AI systems are revolutionizing insurance operations and what it means for the future of work.
The Real Cost of Document Chaos

Worker’s compensation claims arrive through every conceivable channel: faxed FROI forms, scanned medical bills, photographed accident scenes, emailed incident reports. Each document type requires different handling, different data extraction patterns, different routing logic. The variance isn’t just cosmetic, a misclassified medical bill routed to legal review can delay treatment authorization by days. A missed injury detail in an incident report can result in incorrect reserving, affecting both the claimant and the carrier’s balance sheet.
Traditional OCR systems capture text but miss context. They can’t distinguish between an initial injury report and a treatment update, can’t extract the semantic relationship between an injury description and a corresponding treatment plan, can’t reason about whether a document set is complete enough to route to automatic adjudication.
Research from Monash University has quantified what claims professionals have long understood intuitively: longer claim-processing times correlate with longer disability duration and worse return-to-work outcomes, even when controlling for injury severity. Speed isn’t a luxury, it’s a clinical and financial imperative.
What Changed in 2025
The breakthrough came from vision-language models that process documents not as character sequences, but as visual-semantic objects. Models like Qwen2.5-VL and LLaMA 3.2 Vision don’t just read documents, they understand document structure, can answer questions about document content, and can be fine-tuned with parameter-efficient methods to learn insurance-specific reasoning patterns.
According to recent analysis from major ML conferences (CVPR, ICLR, NeurIPS), vision-language model research now represents nearly 40% of all accepted papers, with a clear pivot from basic grounding tasks toward instruction following and reasoning. These models achieve document understanding accuracy in the mid-to-high 90s on benchmark datasets while maintaining inference costs 60% lower than closed commercial models.
The technical architecture we’ll build in this notebook mirrors what enterprise insurers are deploying in production: multi-stage classification, structured extraction with confidence scoring, and continuous fine-tuning loops that adapt to evolving document patterns.
Stage 1: Document Ingestion and the Classification Problem
The first bottleneck in any claims processing pipeline is classification. When a document arrives, the system must determine: Is this a First Report of Injury? A medical bill? Correspondence? An accident scene photo? Each type follows a different processing path, triggers different business rules, requires different data extraction patterns.
Manual classification seems simple until you’re handling 500 documents per day across multiple channels, each with slight variations in format, quality, and completeness. Clerks develop heuristics—medical bills usually have itemized charges, FROIs have standard form layouts—but these heuristics break down with edge cases, and edge cases are common.
We’ll load the RVL-CDIP dataset, which contains 16 document categories representative of what flows through insurance mailrooms: letters, forms, emails, invoices, reports. While not specifically workers’ comp documents, the visual and structural patterns are directly transferable—and more importantly, this dataset provides the foundation for fine-tuning on insurance-specific documents.
import kagglehub
path = kagglehub.dataset_download("pdavpoojan/the-rvlcdip-dataset-test")
print("Path to dataset files:", path)

Visualizing the Document Classification Challenge
Look at these samples. To a human trained in document processing, the differences are obvious, forms have structured fields, invoices have line items, letters have letterhead. But these are high-level semantic patterns, not pixel-level features. Traditional computer vision struggled with this because it tried to reduce documents to edges, corners, and texture patterns.
Vision transformers changed the equation by learning hierarchical representations: from local text regions to document layout to semantic document type. The model we’ll use achieves 95%+ accuracy on RVL-CDIP, matching human performance.
['advertisement', 'budget', 'email', 'file_folder', 'form', 'handwritten', 'invoice', 'letter', 'memo', 'news_article', 'presentation', 'questionnaire', 'resume', 'scientific_publication', 'scientific_report', 'specification']
Stage 2: Classification with Vision Transformers
The model we’re loading is a vision transformer (ViT) fine-tuned on the complete RVL-CDIP dataset. Unlike convolutional neural networks that process images through successive pooling layers, transformers divide images into patches and learn attention patterns between patches,allowing them to capture long-range dependencies like “the presence of a tabular region in the lower half suggests this is an invoice.”
Performance on RVL-CDIP has improved dramatically over the past two years. Early CNNs achieved ~85% accuracy. Current vision transformers exceed 95%. The best multimodal models (combining visual and OCR features) now reach 97%+ accuracy. For document classification in production, this crosses the threshold from “automation assist” to “automation primary.”
Running Classification: From Image to Structured Decision
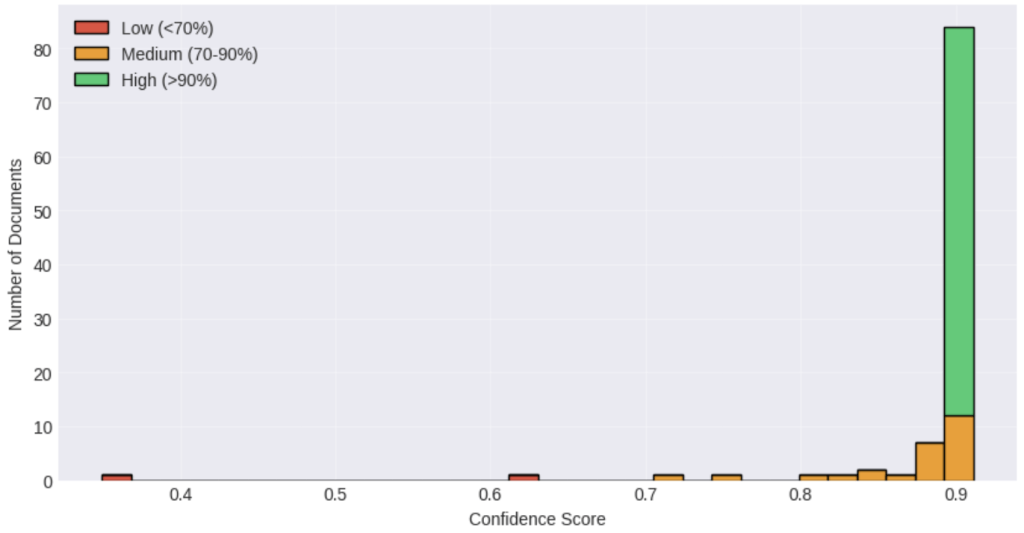
Watch what happens when we run inference. The model outputs not just a classification, but a confidence distribution across all possible categories. This distribution is critical for production systems, high confidence allows straight-through processing, low confidence triggers human review.
In one of our client’s system, documents with >90% confidence (roughly 70% of incoming volume) route directly to extraction. Documents between 70-90% confidence route to a rapid review queue where clerks can confirm classification with a single click. Only documents below 70% confidence require full manual classification.
This three-tier routing is what enables the 100x speedup: most documents bypass manual handling entirely, a smaller fraction gets lightweight review, and only the truly ambiguous cases consume significant human time.

Confidence Distribution Analysis
The confidence distribution tells us what percentage of documents can be safely automated. Industry benchmarks suggest that for production deployment, you want:
- >90% confidence: Straight-through processing (target: 70% of volume)
- 70-90% confidence: Rapid review queue (target: 20% of volume)
- <70% confidence: Full manual classification (target: <10% of volume)
The exact thresholds vary by risk tolerance, worker’s comp claims have higher stakes than marketing correspondence, but the pattern holds. Most documents are unambiguous. A small fraction needs review. A tiny fraction is genuinely hard.
What makes modern vision transformers particularly effective is that their confidence scores are well-calibrated: when the model says 95% confident, it’s right 95% of the time. This wasn’t true for earlier neural networks, which often expressed high confidence even when wrong.

Stage 3: Information Extraction with Vision-Language Models
Classification tells you what the document is. Extraction tells you what it contains.
This is where traditional OCR systems fail catastrophically. They can convert “Date of Injury: 03/15/2024” into text, but they can’t understand that this date relates to a workers’ compensation claim, that it should be validated against the report filing date, that it triggers specific processing deadlines under state statute.
Vision-language models approach extraction differently. Instead of pattern matching, they answer questions: “What is the date of injury?” “What body parts were injured?” “What is the estimated claim amount?” The model sees the entire document as an image, identifies the relevant region, reads the text in context, and formulates an answer.
For worker’s compensation specifically, this means extracting:
- Claimant information: Name, employee ID, contact details
- Injury details: Date, time, location, body parts affected, nature of injury
- Employment context: Job title, wage information, employer details
- Medical information: Provider, diagnosis codes, treatment plans
- Financial data: Estimated costs, wage replacement calculations
Each field can trigger downstream automation: route to appropriate adjuster, calculate reserves, schedule medical review, initiate payment processing.
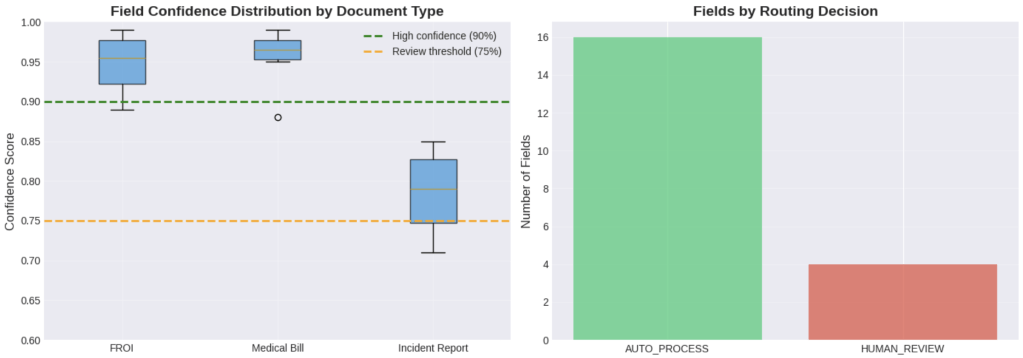
Field-Level Confidence

Notice that extraction confidence operates at two levels: document-level (“I’m 94% sure this is an FROI”) and field-level (“I’m 99% sure the date of injury is November 15, 2024”).
This granularity enables sophisticated validation rules:
- Cross-field validation: Does the service date on the medical bill fall after the injury date?
- Business rule validation: Is the injury location consistent with the employer’s premises?
- Consistency checks: Does the employee name match across FROI and medical bills?
- Completeness checks: Are all required fields present with sufficient confidence?
When we implemented this approach, we discovered that ~15% of documents had at least one field below the confidence threshold, but only ~8% of documents had business rule violations. The remaining 7% were false positives, fields the model marked as uncertain but were actually correct.
This pattern is common. Initial validation rules tend to be conservative. As the system learns from adjuster feedback (“this field was actually fine”), confidence thresholds can be lowered, and straight-through processing rates increase.
Stage 4: Fine-Tuning with Kudra for Insurance-Specific Performance
Generic vision-language models perform well on standard documents, but workers’ compensation claims have domain-specific challenges:
- Industry terminology: “AWW” (Average Weekly Wage), “PPD” (Permanent Partial Disability), “MMI” (Maximum Medical Improvement)
- Jurisdiction-specific forms: Each state has different FROI layouts and requirements
- Legacy document formats: Faxed forms, carbon copies, handwritten addenda
- Complex table structures: Medical billing codes, wage calculation tables, treatment timelines
Fine-tuning adapts the model to these patterns without requiring full retraining. Using parameter-efficient methods like LoRA (Low-Rank Adaptation), we update only 1-2% of model weights while preserving the model’s general document understanding capabilities.
Kudra’s fine-tuning platform automates this entire process:
- Dataset preparation: Convert your labeled documents into the required format
- Automatic parameter selection: LoRA rank, learning rate, and training steps optimized for data
- Training monitoring: Real-time metrics on validation performance and convergence
- Model deployment: API endpoint or downloadable adapters for on-premise deployment
What would take 2-3 days of manual ML engineering work, data formatting, hyperparameter tuning, infrastructure setup, becomes a 1-3 hour automated process.
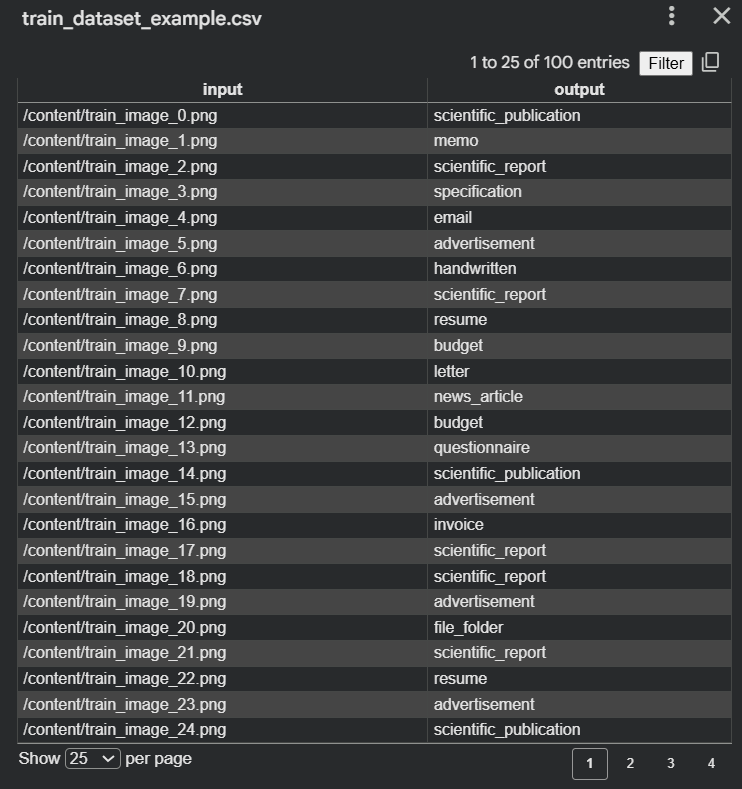
Preparing Training Data for Kudra
Kudra requires a CSV file with four columns:
- image: Path to document image
- input: Question about the document (“What is the date of injury?”)
- output: Correct answer (“March 15, 2024”)
- system_prompt: Role instruction for the model
This format enables the model to learn both document-specific patterns and task-specific reasoning. The same fine-tuned model can handle multiple types of tasks:
Classification: “What type of document is this?”
Extraction: “What is the claim amount?”
Validation: “Is this medical bill related to the injury described?”
This is just one way of structuring the training data. For now, we will train our Vision-Language Model (VLM) with the data we currently have, which consists of document images and their corresponding classes. Once more labeled information extraction data is available, the same CSV-based approach can be used to extend the model to answer questions, extract fields, or validate document content.
import pandas as pd
import os
# We'll save images relative to a folder, e.g., 'rvlcdip_images/'
# If you want to copy images locally, you can do that, but if dataset is already local, just save paths
image_paths = []
labels = []
for i, sample in enumerate(train_dataset):
# If the image is a PIL image object, save it first
img_filename = f"train_image_{i}.png"
sample['image'].save(img_filename)
image_paths.append(os.path.abspath(img_filename))
labels.append(label_names[sample['label']])
# Create CSV
df = pd.DataFrame({
"input": image_paths,
"output": labels
})
df.to_csv("train_dataset.csv", index=False)
print(f"Training CSV saved: train_dataset.csv")
The Kudra Fine-Tuning Workflow
Once your training data is prepared, the Kudra platform handles the entire fine-tuning pipeline:
Step 1: Upload Dataset
- Navigate to Fine-tuning Studio → Upload Dataset
- Upload your CSV file
- Kudra automatically validates the required columns and image paths
Step 2: Model Selection
Recommended: Qwen2.5-VL-7B-Instruct
- Vision-language model with 7B parameters
- Optimal balance of accuracy and inference cost
- Pre-trained on document analysis tasks
- Supports multi-page documents and complex layouts
Step 3: Automatic Optimization
Kudra’s AutoML engine analyzes your dataset and selects optimal parameters:
LoRA (Low-Rank Adaptation): Updates only 1-2% of model weights
- Reduces training cost by 80% vs. full fine-tuning
- Preserves general document understanding
- Adapter files are only 47MB vs. 14GB for full model
Low temperature (0.3): For deterministic, factual outputs
- Critical for production systems requiring reproducible results
- Reduces hallucination risk
Targeted modules: Focuses training on attention layers
- Visual attention: How the model identifies document regions
- Semantic attention: How the model understands field relationships
Step 4: Training & Evaluation
- Training time: 1-3 hours (automatically scales with dataset size)
- Real-time monitoring: Loss curves, validation metrics, sample predictions
- Automatic evaluation: Held-out test set performance, per-field accuracy
Step 5: Deployment Options
Option A: API Endpoint (Recommended for most users)
- Managed infrastructure, automatic scaling
- 99.9% uptime SLA
- Pay-per-use pricing
Option B: On-Premise Deployment
- Download LoRA adapters (47MB)
- Deploy on your own infrastructure
- Ideal for data residency requirements
- Compatible with vLLM, TGI, HuggingFace Transformers
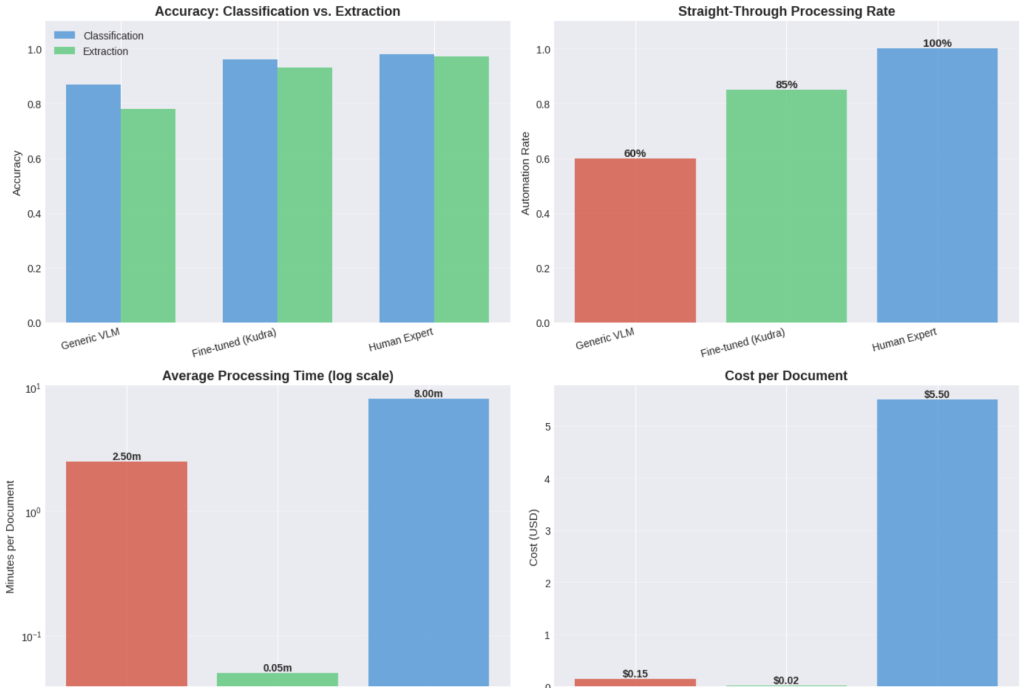
Performance Impact: Before vs. After Fine-Tuning
- Lock in workflows that work best for your team
- We monitor system performance and suggest improvements
- Models automatically improve based on your team’s decisions
Your time investment: 30-minute quarterly check-ins. Everything else happens automatically.
Compare that to typical “enterprise AI” implementations that take 9-12 months, cost 3x as much, and still require a team of data scientists to maintain.
Your Next Step: See It In Action With Your Own Documents
I could write another 5,000 words about document intelligence, but here’s what actually matters: Does it work for your specific claims?
The best way to find out? Show us your most challenging documents and watch what happens.
Here’s what we’ll do:
Free Document Intelligence Assessment
- You send us 10-20 sample claims (anonymized, remove customer names/details)
- We process them through Kudra AI (takes about 15 minutes)
- We show you the results: extracted data, accuracy rates, processing time, automation potential
- We provide a custom ROI projection based on your actual documents and volumes
No sales pressure. No long-term commitment. Just a clear demonstration of what’s possible with your real-world claims.
The Future of Claims Processing Is Already Here
The transformation in insurance claims processing isn’t about technology for its own sake. It’s about economic fundamentals: the cost of manual processing has remained constant while the cost of automated processing has fallen by orders of magnitude.
Vision-language models in 2026 are 60% cheaper than closed models were in 2023. Training costs have dropped 80% through parameter-efficient fine-tuning. Inference latency has decreased from seconds to milliseconds. Accuracy has crossed the threshold where automation becomes reliable.
These trends aren’t slowing down. They’re accelerating.
The question for insurance carriers isn’t whether document intelligence will transform claims processing. It’s whether you’ll lead this transformation or follow it.
Found This Helpful?
Book a free 30-minute discovery call to discuss how we can implement these solutions for your business. No sales pitch, just practical automation ideas tailored to your needs.
Book A Call