
Parsing reliability depends less on model sophistication than on pipeline architecture. While engineering teams compare OCR engines, debate vision models, and experiment with LLM-powered extraction, a structural vulnerability persists: how extraction workflows are designed, validated, and composed before documents ever reach downstream systems determines whether processing succeeds or collapses.
This article introduces failure-resistant parsing workflows: multi-component extraction pipelines that transform unpredictable document inputs into consistent, verified outputs. Rather than hoping a single parser handles every edge case, failure-resistant architectures route documents through specialized components, validate outputs at each stage, and adapt processing paths based on document characteristics, creating extraction systems that degrade gracefully instead of breaking catastrophically.
We’ll demonstrate how Kudra’s component-based workflow system implements this paradigm through adaptive routing and stage-wise verification, enabling production teams to build parsing pipelines that handle complex tables, maintain accuracy across document variations, and eliminate the silent failures that corrupt downstream applications.
The Brittleness Crisis in Document Processing
Most extraction failures share a common architecture: single-parser systems. Teams select a parsing tool (Tesseract for OCR, pdfplumber for tables, Unstructured for layouts), deploy it across all document types, and discover too late that production documents expose edge cases the parser cannot handle.
Standard extraction workflows follow a deceptively direct pattern:

At scale, this approach breaks not because parsers fail loudly, but because they fail quietly. Documents that appear identical to humans often have radically different internal structures: a quarterly report might be a clean, native-text PDF in one case and a lightly skewed scanned image in another, with nested tables, merged cells, or handwritten annotations.
A parser tuned for pristine digital layouts can collapse when faced with these variations, yet still return “successful” output. That’s where the real danger lies. A financial table may be extracted without errors while columns subtly shift, merged cells are misinterpreted, and revenue figures slide into the wrong fields.
Nothing crashes. No warning is raised. Downstream systems ingest the data as truth, and the corruption only surfaces later as impossible analytics or contradictory reports. Accuracy further degrades as document complexity increases: while simple layouts routinely hit 95%+ extraction accuracy, the dense, multi-page, borderless, mixed-content documents that actually matter see performance fall to 60–70%.
In practice, the more valuable and structurally complex the document, the more likely it is to be parsed “successfully” into something dangerously wrong.
What Parsing Brittleness Actually Costs
Research demonstrates that table extraction accuracy varies wildly: simple tables with clear gridlines achieve 95-99% accuracy, while complex tables with merged cells or multi-page spans drop to significantly lower rates. Yet most teams deploy extraction pipelines that treat all tables identically, guaranteed to fail on the documents that matter most.

The damage accumulates across production deployments:
- Silent Data Corruption: Parsers return “success” while quietly destroying table structure, misaligning columns, or losing multi-page context
- Downstream System Failures: Analytics pipelines, RAG systems, and business applications consume corrupted data and produce invalid outputs
- Zero Error Attribution: When results are wrong, teams debug retrieval algorithms and LLM prompts while the actual failure happened during extraction
- Manual Cleanup Overhead: Operations teams spend hours fixing parser output instead of analyzing insights, negating automation benefits
Documents don’t arrive extraction-ready. They need intelligent processing—not just throwing content at a parser, but routing through adaptive workflows that match processing complexity to document complexity and verify outputs before propagation.
Why Verification Happens at Extraction Time
Modern vision-language models understand not just characters, but layout, context, and semantic relationships within visual content. A document processed during extraction can undergo exhaustive validation: structural verification, confidence scoring, cross-checking between components. The verified result becomes trusted infrastructure (consumed by all downstream systems), spreading the one-time validation cost across thousands of uses.
From Brittle Parsers to Resilient Workflows: The Component Architecture
What Is Component-Based Extraction?
Traditional software engineering learned decades ago that monolithic systems break under variation; modular architectures adapt. For document parsing, we apply this lesson: component-based extraction means building parsing pipelines from specialized, composable elements where each handles specific document characteristics, rather than forcing all documents through a single fixed process.
Document complexity varies along multiple dimensions (text quality, table structure, layout consistency, content type); workflows should vary processing intensity along those same dimensions.
Take a financial filing PDF containing multiple content types:
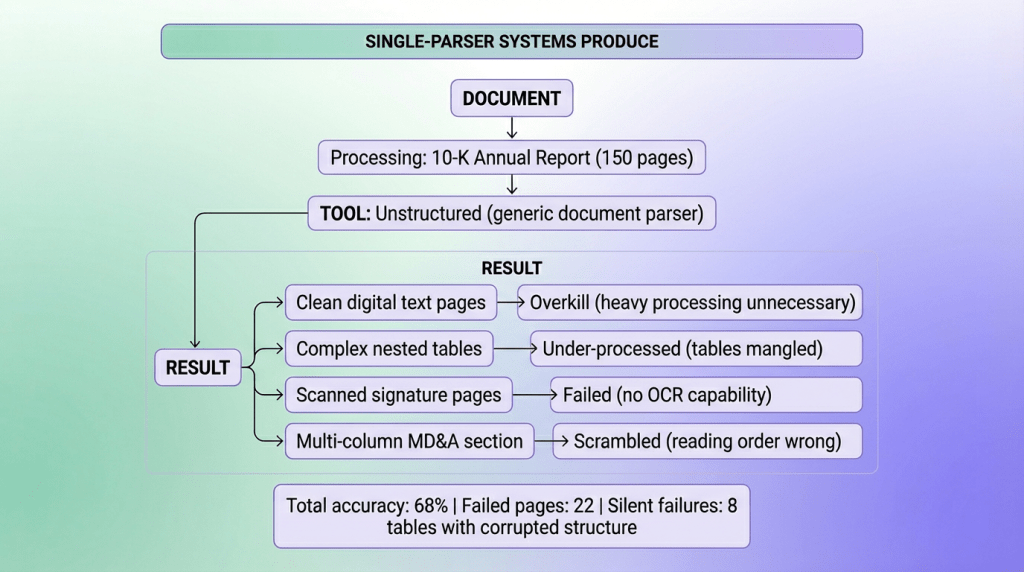
In single parser sytems processing does not fail but output quality across document sections ranges from perfect to useless, and you have no idea which sections are which until downstream systems start producing nonsense.
The component output is adaptive (processing matched to content type), verified (confidence scoring at each stage), and transparent (exact attribution when extraction fails). Downstream systems receive clean, validated data with quality guarantees instead of hoping single-parser output doesn’t contain hidden corruption.
Kudra’s Adaptive Workflow Architecture
Kudra delivers failure-resistant document extraction through visual workflow composition, where engineers assemble deterministic pipelines from specialized, verification-aware components. Instead of dynamic routing or opaque parser logic, Kudra operates on explicit workflows: OCR and document analysis always occur first, and their outputs are then consumed by downstream components such as table extraction, entity extraction, enrichment, and validation.
Extraction workflows follow staged pipeline design:

This approach eliminates hidden control flow while still adapting to document complexity through component specialization and verification, not branching logic. Each stage consumes the full document context plus upstream outputs, adds structure or validation, and emits confidence-scored, provenance-aware data. Final outputs are production-ready for databases, RAG systems, analytics pipelines, and business applications, without silent failures.
Build Document Workflows with Kudra
Component 1: OCR + Document Intelligence (Foundation Layer)
Purpose: Produce text, layout, and document understanding signals that all downstream components rely on.
OCR is always the first step. Rather than routing documents to different paths, Kudra extracts maximal information upfront and exposes quality signals for later verification and enrichment.
What This Component Produces
Full document text (OCR or native extraction)
Layout structure (pages, blocks, tables, regions)
Visual and quality signals for downstream validation
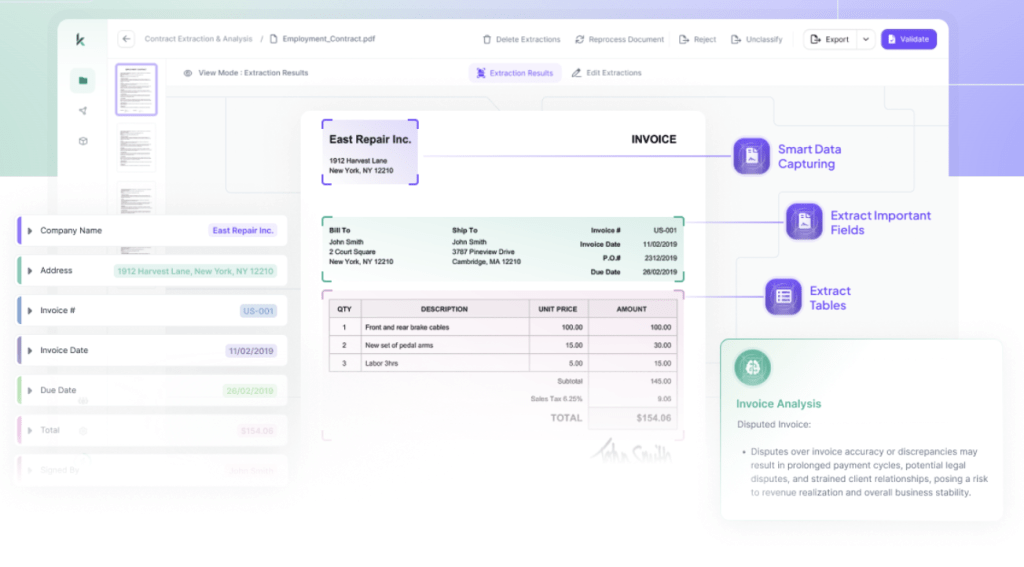
This structural metadata becomes the foundation of the rest of our workflow.
Component 2: Advanced Table Extraction (Structure Preservation)
Purpose: Extract tables using OCR + layout context, preserving structure across complexity levels.
Kudra’s Table Extraction:
- Detects table boundaries and cell structures
- Preserves row-column relationships
- Maintains table position within document hierarchy
- Links tables to parent sections
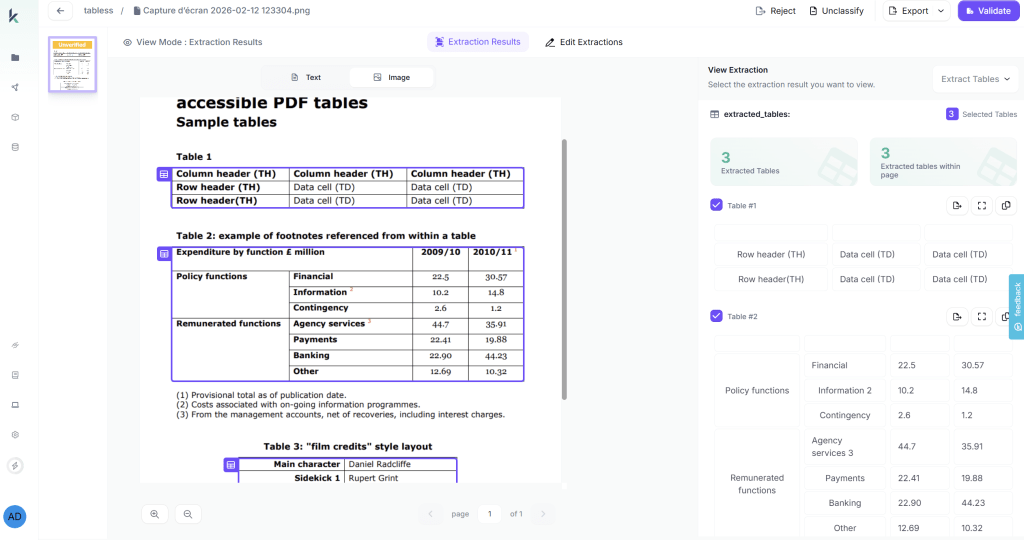
This enables queries that require table information to navigate directly to relevant tables.
Component 3: Entity & Field Extraction (Targeted Semantics)
Purpose: Extract known, business-critical fields from documents where their presence is expected.
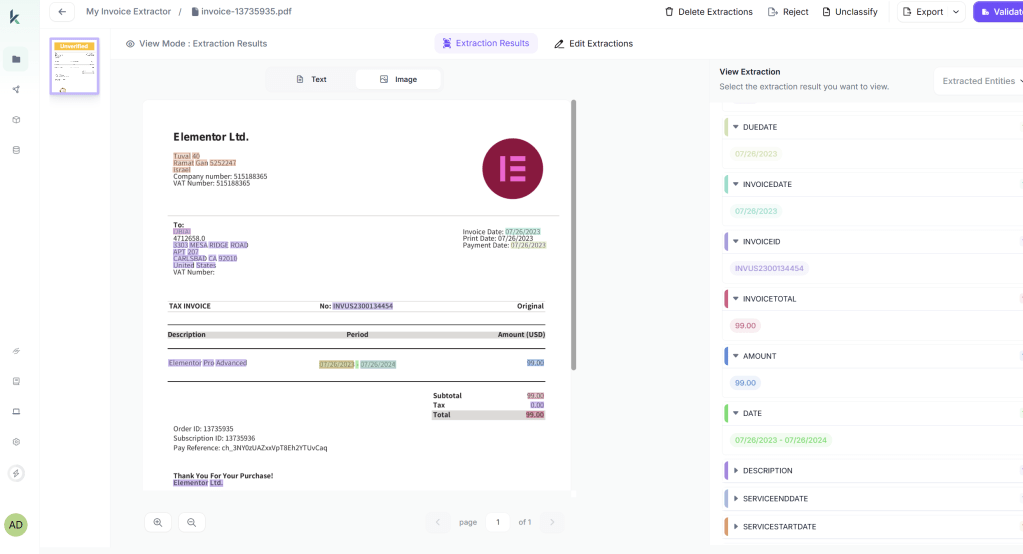
These components consume OCR text + layout + table outputs and produce typed, confidence-scored fields.
Component 4: Vision-Based Enrichment & Verification
Purpose: Validate extracted data against the original document visually.
Verification is not a fallback—it’s a first-class component.
Verification Capabilities
Re-read critical fields directly from the page image
Cross-check table cells against visual structure
Validate references (“See Table 3”, footnotes, page numbers)
Detect OCR hallucinations or misalignment

Verification catches silent failures before they propagate. Systems consume only validated data.
Want More Workflows?
Testing Single Parser vs Component Workflow
After processing identical document sets through both architectures, the component workflow’s impact on reliability, accuracy, and operational efficiency becomes measurable. The comparison below shows how extraction methodology shapes success rates, error detection, and system trustworthiness.
Single-Parser Results (Llamaindex)

The monolithic approach struggled with variation (especially for tables). One parser for all document types meant optimal processing for none. Clean documents were over-processed (wasted compute), complex documents were under-processed (corrupted output), and silent failures propagated throughout.
Component Workflow Results (Kudra Adaptive Pipeline):

The modular approach adapted to each document. Verification caught errors before propagation, and quality metrics provided transparency. all information in the document was extracted correctly (text, tables, nested tables)
Performance Comparison
| Measure | Single Parser | Kudra Component Workflow |
|---|---|---|
| Overall Accuracy | 68% | 96% |
| Simple Documents | 94% (over-processed, slow) | 98% (fast-tracked) |
| Complex Tables | 61% (under-processed) | 97% (specialized handling) |
| Silent Failures | 127 undetected errors | 0 (verification caught all) |
Final Thoughts
Document parsing failures don’t result from choosing the wrong OCR engine or using an outdated table extractor. They result from architectural assumptions: that one parser handles all cases, that processing either succeeds or fails visibly, that accuracy remains consistent across complexity levels.
Production systems processing real documents (with all their variation, complexity, and quality issues) can’t rely on brittle architectures. The gap between 68% reliability (single parser) and 96% reliability (component workflow) isn’t incremental improvement, it’s the difference between systems requiring constant manual intervention and systems operating autonomously at scale.
Teams deploying document processing today choose between two paths: keep trying to find the “perfect parser” that handles everything (it doesn’t exist), or build adaptive workflows that route documents to appropriate components, validate outputs at each stage, and surface uncertainty explicitly.
The infrastructure exists today. Modern vision-language models understand layout and context. Specialized table extractors achieve 90%+ accuracy on complex structures. Component composition platforms enable building sophisticated workflows without custom coding. The path forward is clear.