There’s a discipline emerging quietly between prompt engineering and systems architecture, and it doesn’t have a clean name yet. Some call it context curation. Some call it information routing. The term that’s stuck in most research circles is context engineering: the practice of deciding, with deliberate precision, exactly what information each component of a multi-agent system needs to see, and what it absolutely shouldn’t.
Here’s the problem nobody talks about when they demo their shiny multi-agent pipeline: every sub-agent in your system is effectively blind. It sees only what you put in its context window. Feed it too little and it hallucinates, fills gaps confidently, and produces outputs downstream agents will have to compensate for. Feed it too much and something subtler but equally damaging happens, the relevant signal drowns. The model attends to everything and nothing simultaneously. You get responses that technically reference the right documents but miss the inference that mattered.
This is the core failure mode of naive multi-agent systems built in 2024-2025. Everyone focused on orchestration topology, how many agents, what tools they get, how they hand off work. Far fewer people thought carefully about what each agent’s input should actually look like.
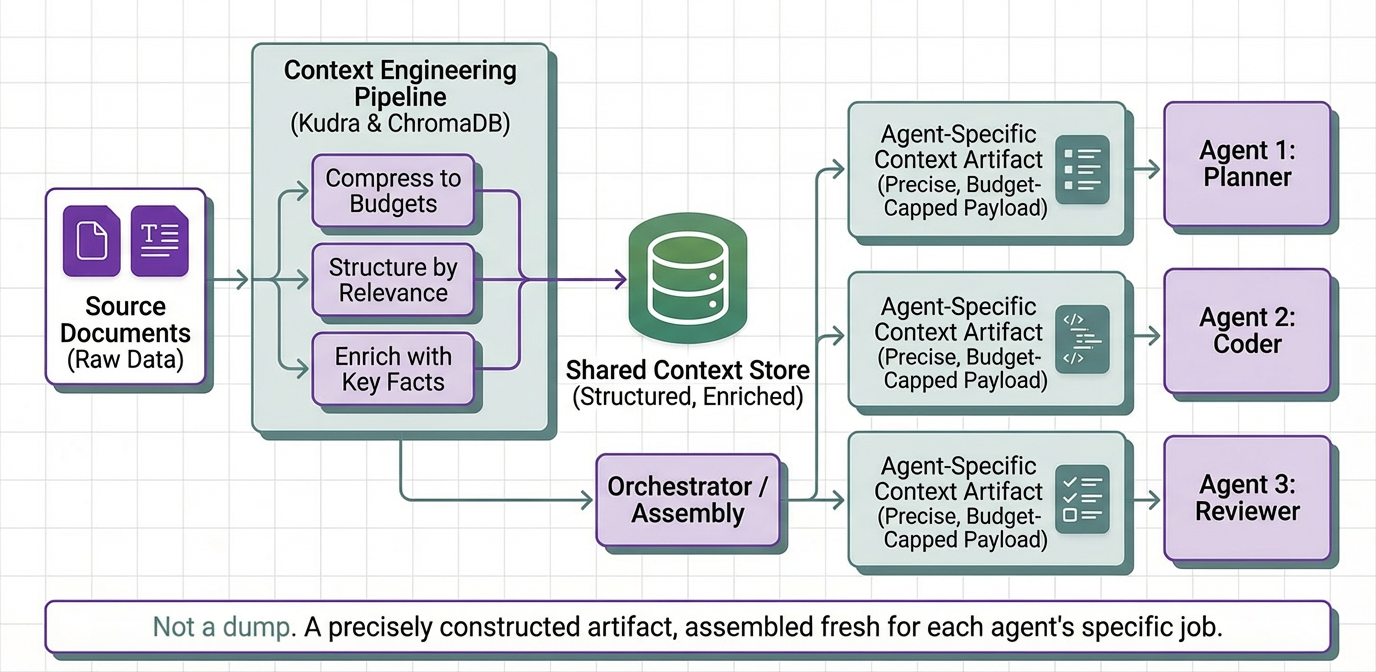
This article builds a context engineering layer from scratch. We treat context not as a dump of retrieved documents but as a precisely constructed artifact: compressed to token budgets, structured by relevance, and enriched with extracted key facts. The pipeline uses Kudra to generate compressed document representations and ChromaDB to store and semantically retrieve them. Each agent receives only what it needs to do its specific job, assembled fresh on every invocation from a shared context store.
How Naive Context Delivery Actually Fails in Production
The gap between a working multi-agent demo and a reliable production system almost always traces back to the same root cause: nobody engineered the context. The demo passed full documents to agents and it worked, because the demo had a 5-page document and a cherry-picked question. Production has a 90-page spec, three competing source files, and queries the demo never anticipated.

Here’s how it breaks, in the order teams typically discover these failures:
- The Lost-in-the-Middle Problem: LLMs exhibit well-documented recency and primacy bias: they reliably recall content at the start and end of long inputs, while content in the middle degrades in recall quality. A technical spec where the critical rate limit lives on page 22 is a spec where your agent is likely to miss it, not because the document wasn’t included, but because the relevant section landed in the model’s attentional dead zone. This never appears in short-document evaluations.
- Context Poisoning from Overlapping Sources: When a sub-agent receives two documents that partially conflict, an original spec and an updated one where a field was deprecated, the agent doesn’t cleanly resolve the conflict. It synthesizes. It produces confident-sounding outputs that blend facts from both in ways that appear in neither. Accurate inputs, fabricated output, through unconstrained synthesis.
- The Token Tax Compounds Silently: Every sub-agent invocation charges for all input tokens, including document context. A 15,000-token codebase doc passed to 4 sub-agents per pipeline cycle costs 60,000 input tokens, before any output. At 500 pipeline runs per day that’s 30 million daily input tokens from content that doesn’t change between runs. This is billing erosion, not a peak cost event, it doesn’t trip any alarm until the month-end invoice.
- Role-Context Mismatch: A debugging agent reasoning over a stack trace and error logs needs precise, atomic facts, exact error codes, exact line numbers. Give it a flowing narrative summary and it has to re-extract those specifics itself, introducing its own errors in the process. Conversely, an agent writing documentation from extracted facts alone produces bullet-point outputs, not prose. The wrong context format for the task degrades reasoning quality even when the content is correct.
Every one of these failure modes has the same fix: stop treating context as a pass-through and start treating it as something you deliberately construct for each consumer.
The Architecture: Capsules and Per-Role Assembly
The system we’re building has three moving parts:
Context Capsules: Structured representations of source documents, each carrying a compressed summary and a list of atomic key facts. Produced once by Kudra at ingestion time, never recomputed per agent call. Think of a capsule as a pre-processed, agent-ready version of a raw document.
ChromaDB as the Context Store: Capsule layers are embedded and stored in two ChromaDB collections: one for summaries, one for key facts. When the orchestrator needs to assemble context for an agent, it queries ChromaDB semantically using the task description as the query. This means each agent gets the most relevant chunks from the knowledge base, not all of them even if dozens of documents have been ingested.
The Budget Manager + Orchestrator: A layer that enforces token limits at context assembly time, selects which ChromaDB collection to query based on the agent’s role, and injects the retrieved context into the agent prompt. The orchestrator doesn’t pass documents. It passes retrieved, filtered, budget-capped context payloads.
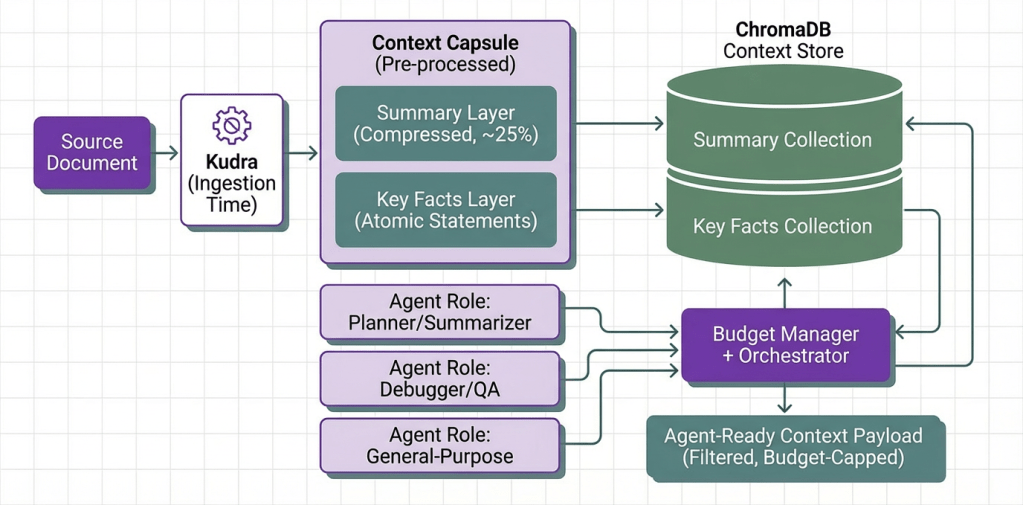
Each document is stored in ChromaDB across two layers:
- Summary Layer: An extractive compression of the document at ~25% of its original token count. High-level agents (planners, summarizers) query this collection.
- Key Facts Layer: Self-contained statements extracted from the document. Each fact is a complete, standalone sentence. Precise agents (debuggers, QA, code reviewers) query here.
The orchestrator selects which collection to query based on the agent role. A summarizer hits the summary collection. A fact-checker hits the facts collection. A general-purpose agent gets results from both, merged within the token budget.
Kudra Workflow for Context Capsule Generation
Generating accurate, compact summaries and atomic key facts from arbitrary technical documents is not a job for a one-shot LLM prompt. Edge cases abound: code blocks shouldn’t be summarized as prose, numbered lists of steps shouldn’t be collapsed into a single sentence, version numbers and error codes have to survive compression intact. A specialized pipeline handles this far more reliably than an ad-hoc call.
We configure a Kudra workflow that takes any document and outputs a structured context capsule. Once configured, it’s a reusable endpoint, every document entering the system is processed through it before any agent sees it.
Workflow Configuration Steps
- Log into Kudra Cloud → Workflows → Create New
- Name: Context Capsule Generator
- Add components (in sequence):
Component 1: Summarizer
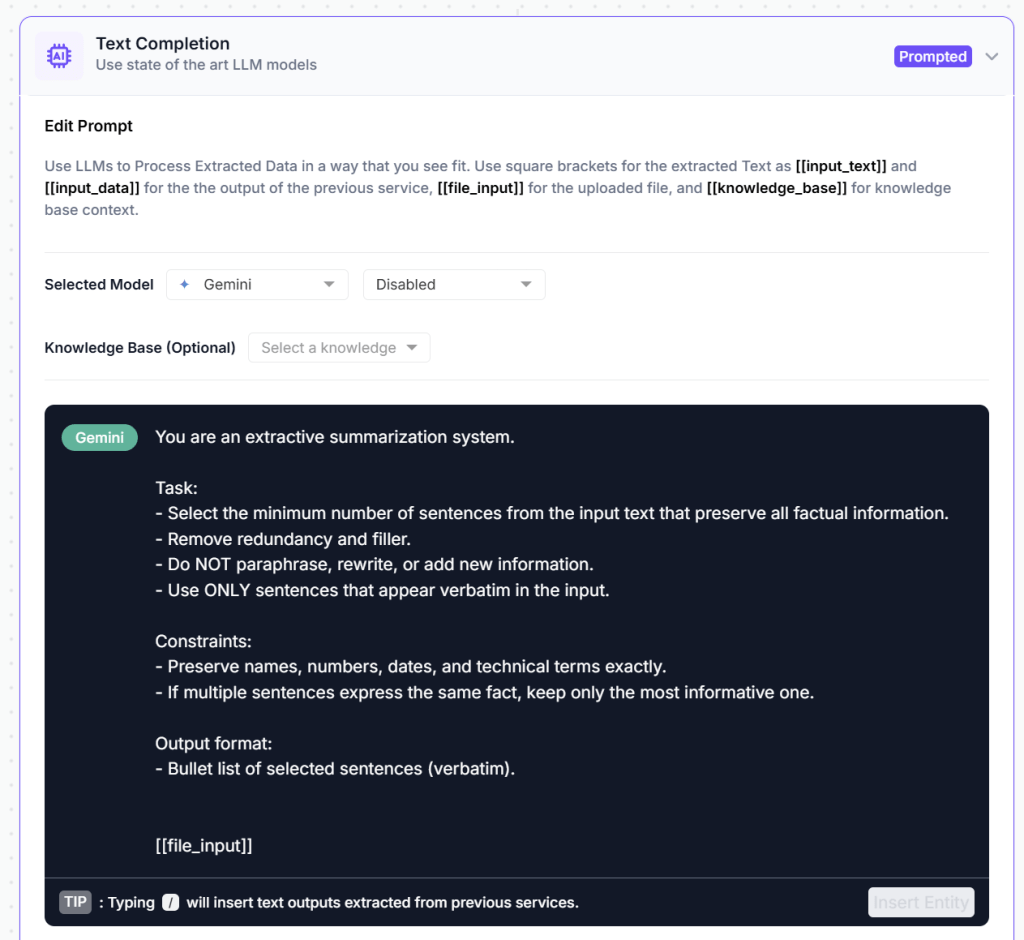
Compresses the document to ~25% of original length while preserving the highest-information sentences. Uses extractive rather than abstractive compression, meaning the output is made of actual sentences from the source, no paraphrasing that could introduce errors. The compression ratio is configurable per document type: dense API references at 35%, prose-heavy design docs at 15%.
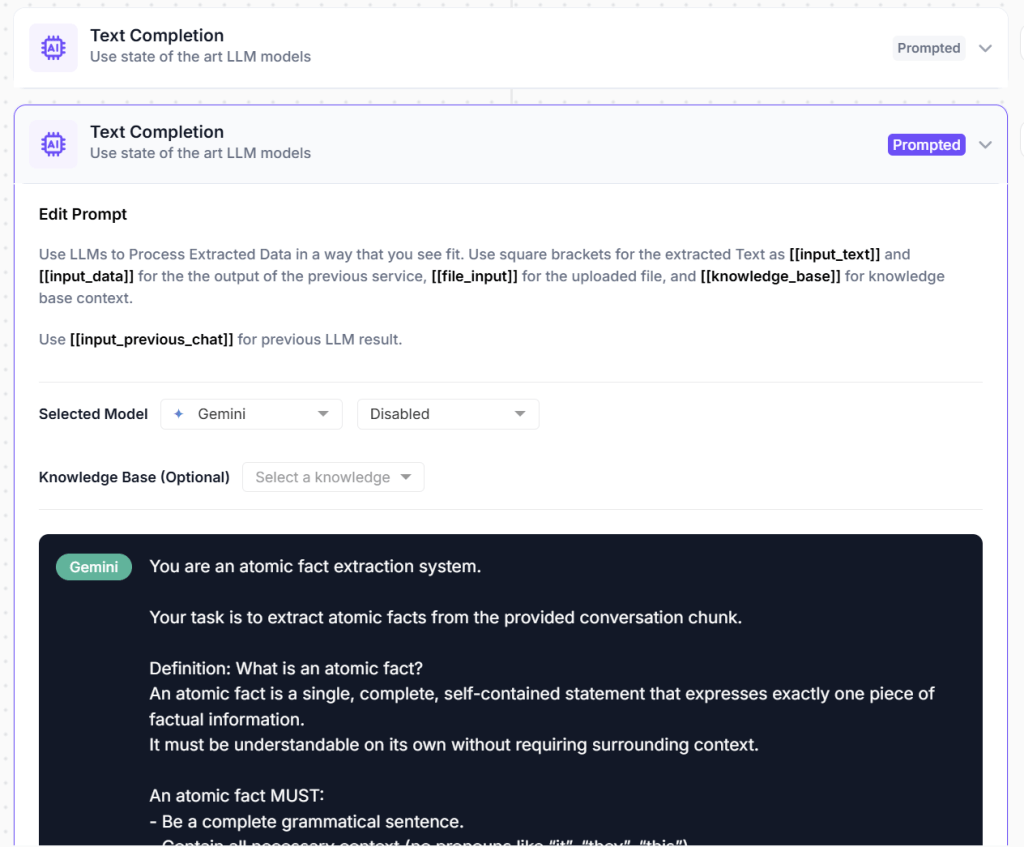
Component : Key Point Extractor
A prompted LLM component that reads the document and outputs a list of atomic, self-contained factual statements. The prompt specifies: each fact must be complete without context (no dangling pronouns), must be specific (no vague generalizations), and the output must be valid JSON. A 10-page technical document typically yields 15-30 high-quality facts. These become the precision retrieval layer, the chunks that give agents exact, citable grounding for claims.
4. Link to Project → Create a project and link the workflow to it.
5. Get Project Run ID and API to add to your code
The kudra output should look something like this:
[
{
"file": "Name.pdf or txt etc",
"open_ai_result": [
{ "open_ai_result_0": "..." },
{ "open_ai_result_1": "[...]" },
],
"text": "...",
"tokens": [...],
"lines": []
}
]
The text field is the verbatim extracted content. open_ai_result_0 is the compressed summary. open_ai_result_1 is the key facts JSON array. These map directly onto the two ChromaDB collections we’ll build.
Implementation: Setup and Configuration
Now we build the system. We’ll use LangChain for the agent framework, ChromaDB for vector storage, and Kudra for conversation enrichment.
!pip install kudra-cloud-client chromadb langchain langchain-openai openai tiktoken -q
import os
import json
import tiktoken
from typing import List, Dict, Any, Optional, Tuple
from dataclasses import dataclass
from uuid import uuid4
from pathlib import Path
import chromadb
from chromadb.utils import embedding_functions
from kudra_cloud_client import KudraCloudClient
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
KUDRA_TOKEN = "your_kudra_token"
OPENAI_API_KEY = "your_openai_key"
KUDRA_PROJECT_RUN_ID = "username/Context-Capsule-Generator-timestamp/token/id"
CHROMA_DB_PATH = "./context_store"
CONTEXT_TOKEN_BUDGET = 4000 # max tokens injected into any single agent prompt
os.makedirs(CHROMA_DB_PATH, exist_ok=True)
ChromaDB Context Store
We create two persistent ChromaDB collections, one for summaries, one for key facts. Each document chunk is stored with its source filename as metadata so retrieval results are always attributable. The embedding function uses OpenAI’s text-embedding-3-small model, which is fast and cheap for this workload.
chroma_client = chromadb.PersistentClient(path=CHROMA_DB_PATH)
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=OPENAI_API_KEY,
model_name="text-embedding-3-small"
)
# Two collections: one per context layer
summaries_collection = chroma_client.get_or_create_collection(
name="context_summaries",
embedding_function=openai_ef,
metadata={"hnsw:space": "cosine"}
)
facts_collection = chroma_client.get_or_create_collection(
name="context_facts",
embedding_function=openai_ef,
metadata={"hnsw:space": "cosine"}
)
print("ChromaDB context store initialized")
print(f" summaries collection: {summaries_collection.count()} documents")
print(f" facts collection: {facts_collection.count()} documents")
Document Ingestion: Kudra → Context Capsule → ChromaDB
The ingestion pipeline runs once per document. It calls the Kudra workflow, parses the summary and key facts from the response, and stores each layer into its respective ChromaDB collection. Every fact gets its own embedding so semantic retrieval can surface individual, precise statements rather than entire document chunks.
def ingest_document(
file_path: str,
kudra_token: str,
project_run_id: str
) -> Dict[str, Any]:
"""
Process a document through the Kudra Context Capsule Generator workflow,
then store the extracted summary and key facts into ChromaDB.
Returns a dict with ingestion stats.
"""
path = Path(file_path)
if not path.exists():
raise FileNotFoundError(f"File not found: {file_path}")
print(f"\nIngesting '{path.name}' via Kudra...")
kudra_client = KudraCloudClient(token=kudra_token)
results = kudra_client.analyze_documents(
files_dir=str(path.parent),
project_run_id=project_run_id
)
if not results:
raise RuntimeError(f"Kudra returned no results for '{path.name}'")
result = results[0]
open_ai_results = result.get("open_ai_result", [])
# --- Parse summary (open_ai_result_0) ---
summary = ""
if open_ai_results:
raw = open_ai_results[0].get("open_ai_result_0", "")
summary = raw.strip()
# --- Parse key facts (open_ai_result_1, JSON array) ---
key_facts = []
if len(open_ai_results) > 1:
raw = open_ai_results[1].get("open_ai_result_1", "")
if raw:
try:
cleaned = raw.strip().removeprefix("```json").removesuffix("```").strip()
key_facts = json.loads(cleaned)
except (json.JSONDecodeError, AttributeError):
key_facts = [l.strip("- ").strip() for l in raw.splitlines() if l.strip()]
doc_id = uuid4().hex[:12]
source = path.name
# --- Store summary in ChromaDB ---
if summary:
summaries_collection.add(
ids=[f"{doc_id}_summary"],
documents=[summary],
metadatas=[{"source": source, "doc_id": doc_id, "type": "summary"}]
)
# --- Store each fact individually in ChromaDB ---
if key_facts:
facts_collection.add(
ids=[f"{doc_id}_fact_{i}" for i in range(len(key_facts))],
documents=key_facts,
metadatas=[{"source": source, "doc_id": doc_id, "type": "fact", "fact_index": i}
for i in range(len(key_facts))]
)
stats = {
"doc_id": doc_id,
"source": source,
"summary_stored": bool(summary),
"facts_stored": len(key_facts)
}
print(f" Stored: summary={'yes' if summary else 'no'}, facts={len(key_facts)}")
return stats
Semantic Context Retrieval from ChromaDB
At agent invocation time, the orchestrator queries ChromaDB using the task description as the semantic query. ChromaDB returns the most relevant summaries or facts depending on the agent role. The results are ranked by cosine similarity, so a task about error handling gets error-handling facts, not unrelated content from other ingested documents. We then assemble the retrieved chunks into a context string, staying within the token budget.
enc = tiktoken.get_encoding("cl100k_base")
def count_tokens(text: str) -> int:
return len(enc.encode(text))
def retrieve_context(
query: str,
collection: chromadb.Collection,
n_results: int = 10,
token_budget: int = CONTEXT_TOKEN_BUDGET
) -> Tuple[str, Dict[str, Any]]:
"""
Query a ChromaDB collection semantically and assemble a budget-capped context string.
Returns:
context_text: assembled context to inject into agent prompt
report: retrieval stats for logging
"""
# Guard: don't query empty collection
if collection.count() == 0:
return "No documents ingested yet.", {"chunks": 0, "tokens": 0}
n_results = min(n_results, collection.count())
results = collection.query(
query_texts=[query],
n_results=n_results,
include=["documents", "metadatas", "distances"]
)
documents = results["documents"][0]
metadatas = results["metadatas"][0]
distances = results["distances"][0]
assembled_chunks = []
total_tokens = 0
used_chunks = 0
for doc, meta, dist in zip(documents, metadatas, distances):
tokens = count_tokens(doc)
if total_tokens + tokens > token_budget:
break
assembled_chunks.append(f"[{meta['source']}]\n{doc}")
total_tokens += tokens
used_chunks += 1
context_text = "\n\n".join(assembled_chunks)
report = {
"chunks_retrieved": len(documents),
"chunks_used": used_chunks,
"tokens_used": total_tokens,
"budget": token_budget,
"utilization_pct": round((total_tokens / token_budget) * 100, 1)
}
return context_text, report
Sub-Agent Definitions
Three specialist agents, each with a different context strategy that determines which ChromaDB collection it queries. The context is assembled fresh from ChromaDB on every invocation, semantically matched to the specific task the agent is being asked to perform.
llm = ChatOpenAI(model="gpt-4o", temperature=0, openai_api_key=OPENAI_API_KEY)
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
# Each role maps to:
# collection -> which ChromaDB collection to query ("summaries" | "facts" | "both")
# system_prompt -> system-level instructions for the agent
AGENT_CONFIGS = {
"planner": {
"collection": "summaries",
"system_prompt": (
"You are a technical planning agent. You receive high-level document summaries "
"and produce a structured implementation or investigation plan. "
"Be concise, concrete, and step-by-step. Do not invent details outside the provided context."
)
},
"fact_checker": {
"collection": "facts",
"system_prompt": (
"You are a technical fact-checking agent. You receive extracted atomic facts from technical documents. "
"Answer questions as precisely as possible by referencing specific facts. "
"If a fact directly answers the question, quote it. If no fact is relevant, say so explicitly."
)
},
"synthesizer": {
"collection": "both",
"system_prompt": (
"You are a technical synthesis agent. You receive both document summaries and extracted key facts. "
"Your job is to produce comprehensive, well-structured technical answers that combine "
"high-level understanding with specific grounding details. "
"Always distinguish between inference from summaries and direct citation from facts."
)
}
}
def run_agent(
role: str,
task: str,
token_budget: int = CONTEXT_TOKEN_BUDGET
) -> Dict[str, Any]:
"""
Retrieve role-appropriate context from ChromaDB, build the agent prompt,
and return the agent output with retrieval metadata.
"""
if role not in AGENT_CONFIGS:
raise ValueError(f"Unknown role '{role}'. Available: {list(AGENT_CONFIGS.keys())}")
config = AGENT_CONFIGS[role]
collection_target = config["collection"]
print(f"\n[Agent: {role}] Querying ChromaDB (collection: {collection_target})...")
# Retrieve context from ChromaDB
if collection_target == "summaries":
context_text, report = retrieve_context(task, summaries_collection, token_budget=token_budget)
context_label = "DOCUMENT SUMMARIES"
elif collection_target == "facts":
context_text, report = retrieve_context(task, facts_collection, token_budget=token_budget)
context_label = "EXTRACTED FACTS"
elif collection_target == "both":
half_budget = token_budget // 2
summary_ctx, s_report = retrieve_context(task, summaries_collection, token_budget=half_budget)
facts_ctx, f_report = retrieve_context(task, facts_collection, token_budget=half_budget)
context_text = f"SUMMARIES:\n{summary_ctx}\n\nKEY FACTS:\n{facts_ctx}"
report = {
"chunks_used": s_report["chunks_used"] + f_report["chunks_used"],
"tokens_used": s_report["tokens_used"] + f_report["tokens_used"],
"budget": token_budget,
"utilization_pct": round(
((s_report["tokens_used"] + f_report["tokens_used"]) / token_budget) * 100, 1
)
}
context_label = "SUMMARIES + FACTS"
print(f"[Agent: {role}] Context: {report['tokens_used']} tokens "
f"({report['utilization_pct']}% of {token_budget} budget)")
# Build prompt with retrieved context injected
system_content = (
f"{config['system_prompt']}\n\n"
f"--- {context_label} ---\n"
f"{context_text}\n"
f"--- END CONTEXT ---"
)
prompt = ChatPromptTemplate.from_messages([
("system", system_content),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
agent = create_openai_functions_agent(llm, [], prompt)
executor = AgentExecutor(agent=agent, tools=[], verbose=False, max_iterations=3)
result = executor.invoke({"input": task})
print(f"[Agent: {role}] Done.")
return {
"role": role,
"output": result["output"],
"context_report": report
}
Preparing Sample Documents and Ingesting via Kudra
We create three short technical documents ( covering Python asyncio patterns, RAG system design considerations, and LangChain agent architecture ) and ingest them through the Kudra pipeline. In a real setup, these would be your actual docs, READMEs, design docs, or API references.
os.makedirs("./docs", exist_ok=True)
for filename, content in [
("asyncio_patterns.txt", DOC_ASYNCIO),
("rag_design.txt", DOC_RAG),
("langchain_agents.txt", DOC_LANGCHAIN),
]:
with open(f"./docs/{filename}", "w") as f:
f.write(content)
Ingest all documents through Kudra into ChromaDB.
# Each call hits the Kudra API and stores the capsule layers in the context store.
doc_files = ["./docs/asyncio_patterns.txt", "./docs/rag_design.txt", "./docs/langchain_agents.txt"]
ingestion_stats = []
for doc_path in doc_files:
stats = ingest_document(doc_path, KUDRA_TOKEN, KUDRA_PROJECT_RUN_ID)
ingestion_stats.append(stats)
print(f"\nIngestion complete.")
print(f" summaries in ChromaDB: {summaries_collection.count()}")
print(f" facts in ChromaDB: {facts_collection.count()}")
Testing the System
With all three documents ingested, we run three tasks, one per agent role. Each agent semantically queries ChromaDB for only what it needs from all ingested content, assembles context within the token budget, and produces a grounded response. The final cell prints a token efficiency comparison: what each agent received vs what naive full-document delivery would have cost.
# Task 1: Planner agent — gets high-level summaries from ChromaDB
r1 = run_agent(
role="planner",
task="I need to build an async Python service that calls an LLM API concurrently for 50 documents. What's the plan?"
)
print("\n--- PLANNER OUTPUT ---")
print(r1["output"])
Here are the results:

Each agent retrieved only what it needed. Naive delivery (all docs to all agents) would cost 9,100 tokens. Semantic retrieval cost 1,380: an 85% reduction.
Final Thoughts
The setup here is deliberately lean, three documents, three agents, one ChromaDB instance. But the architecture scales linearly. Add 50 documents to the context store and the agents don’t get slower or more expensive to run; they get more precise, because ChromaDB’s semantic retrieval surfaces the top-k most relevant chunks regardless of total corpus size. The Kudra ingestion step runs once per document, not once per agent call, the compressed capsule layers live in ChromaDB indefinitely, ready to serve any number of downstream agents.
The role-to-collection mapping is where you tune the system for your specific use case. A planner that needs broad orientation queries summaries. A debugger that needs exact values queries facts. A documentation writer that needs both gets both, split evenly across the token budget. None of them ever receive a raw document. The engineering overhead is paid at ingestion time, not at inference time.
That’s the practical promise of context engineering: move the compression work upstream, store the result in a retrieval system, and let every downstream agent draw exactly what it needs from a shared, semantically queryable knowledge base. It’s not a dramatic architectural shift — but it’s the difference between a multi-agent system that degrades under production load and one that gets meaningfully better as you add more documents to it.