Vector search has dominated RAG for the past few years with Vector embeddings being the default answer to document retrieval. It promises to understand “meaning” and return the most relevant chunks. But production RAG systems tell a different story: query accuracy plateaus around 70-75% regardless of embedding model choice, and the remaining errors trace back to a fundamental architectural assumption: that semantic similarity is the right way to navigate documents.
What if this assumption is wrong? Financial reports aren’t organized by semantic similarity. They follow strict hierarchical structures: sections contain subsections, tables reference specific fiscal periods, footnotes clarify specific line items. Medical records organize information by encounter date, diagnostic category, and treatment timeline. Legal contracts nest clauses within articles within schedules. When humans search these documents, they don’t rely on fuzzy similarity, they navigate structure.
This article introduces vectorless RAG through document tree navigation: a reasoning-based retrieval approach that moves away from chunking and similarity search, building hierarchical document trees that LLMs can navigate like experts reading a table of contents. Rather than retrieving “similar text,” vectorless RAG enables agents to reason about where to look and why, following cross-references, understanding section relationships, and navigating complex documents with logarithmic search complexity.
Here we demonstrate how Kudra’s extraction pipeline produces structured document trees suitable for vectorless retrieval, and show how agentic RAG systems built on document structure achieve superior accuracy with dramatically lower token consumption. The difference isn’t marginal but the gap between systems that guess at relevance and systems that know where information lives.
The Similarity Search Problem in Traditional RAG
In 2026, the majority of RAG systems still follow a pattern established in 2023: chunk documents, create embeddings, retrieve by similarity. This pipeline promised to solve retrieval: encode documents into high-dimensional spaces where semantically similar content clusters together.
Traditional RAG ingestion follows a deceptively simple pattern:
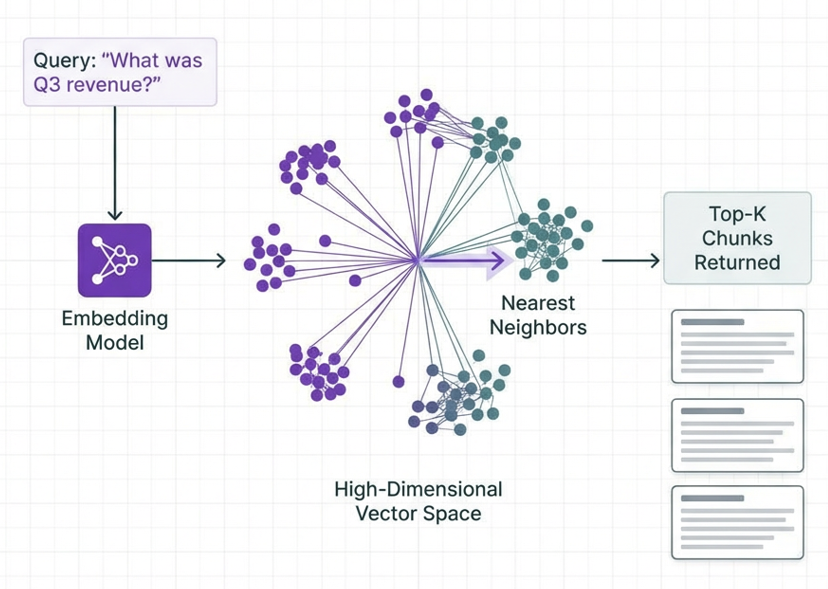
However this approach makes three critical assumptions that break on complex documents:
Assumption 1: Chunking preserves semantic units Reality: Arbitrary token boundaries split tables mid-row, separate section headers from content, and fragment arguments across chunks. A 512-token chunk might contain the end of one concept and the beginning of another, semantically incoherent.
Assumption 2: Semantic similarity indicates relevance Reality: A query about “Q3 2024 revenue growth” might match chunks discussing “revenue” and “growth” in unrelated contexts (product growth, employee growth, historical revenue comparisons). High cosine similarity ≠ answering the question.
Assumption 3: Flat retrieval handles complex documents Reality: Financial reports, legal contracts, and technical manuals have hierarchical structure, sections, subsections, appendices, cross-references. Flattening this into chunks destroys navigational information that experts use to find answers.
The Cost of vector retrieval
Production RAG systems using vector retrieval exhibit predictable failure patterns. When vector search returns marginally relevant chunks, LLMs spend enormous token budgets processing noise:
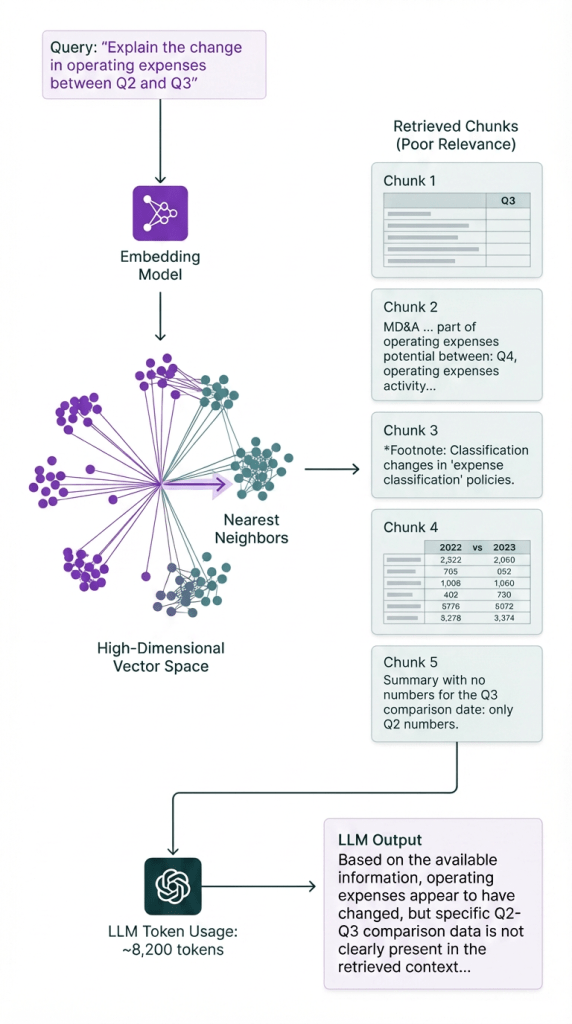
The system hedges because vector search provided the wrong context. Token budget wasted on parsing irrelevant chunks. Answer quality: unusable.
Vector embeddings are structure-blind. They encode semantic content but discard:
- Hierarchical relationships (which section contains which subsection)
- Sequential ordering (financial statements follow standard sequences)
- Cross-references (footnotes refer to specific line items)
- Tabular structure (rows and columns with semantic relationships)
When you chunk a document into 512-token fragments for embedding, you destroy the very information humans use to navigate: “Go to the Income Statement, find the Operating Expenses line, compare Q2 and Q3 columns.” Vector search cannot execute this logic because it doesn’t know what an “Income Statement” is or where to find it: it only knows semantic similarity.
Sadly RAG engineers keep trying to optimize embedding models and rerankers, achieving marginal gains (73% → 75% accuracy), while the fundamental problem remains. You cannot recover structure from semantic similarity. The architecture is solving the wrong problem.
Vectorless RAG: Navigation Over Similarity
What Is Vectorless Retrieval?
In traditional machine learning pipelines, vectors serve as compact numerical representations enabling similarity operations. In RAG systems, we challenge this necessity: vectorless RAG is the process of building structured document representations (hierarchical trees) that LLMs can navigate through reasoning, eliminating the need for embeddings and similarity search.
Vectorless RAG replaces embedding-based search with structure-aware navigation. Documents are not flat text collections but structured knowledge trees where position, hierarchy, and relationships encode meaning.
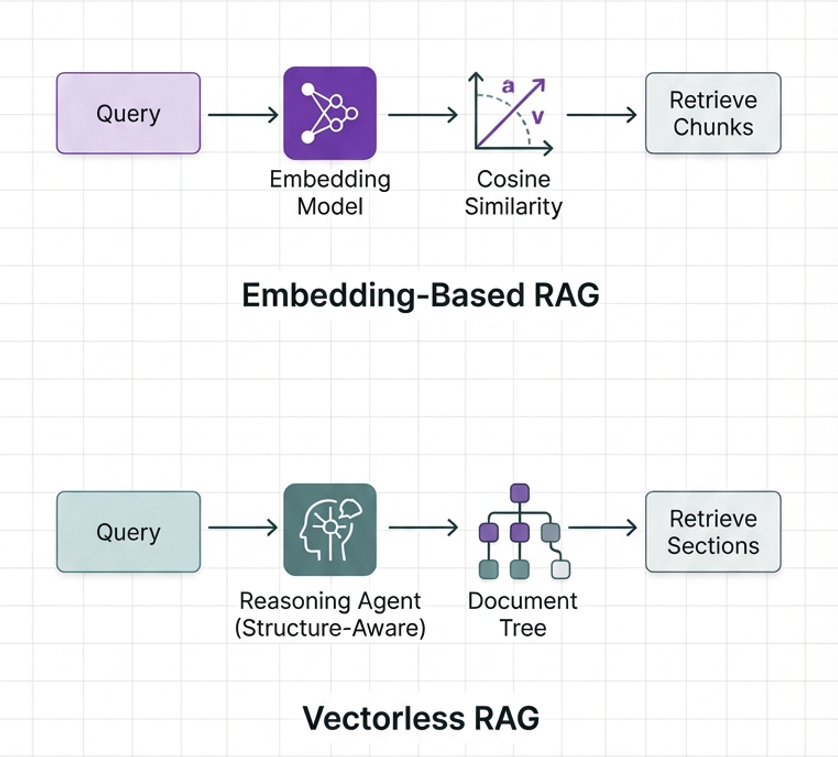
The LLM doesn’t search for semantically similar text but navigates the document using explicit structural information. Just as a human would scan a table of contents, identify the relevant section, and drill down to the specific subsection, the LLM traverses a document tree.
Core components:
- Document tree: Hierarchical representation of document structure (sections, subsections, tables, figures)
- Metadata labels: Semantic descriptions of what each section contains
- Navigational reasoning: LLM decides where to look based on query intent
- Contextual retrieval: Extract full sections with structural context preserved
Documents are already organized. Financial reports follow SEC guidelines. Medical records follow clinical workflows. Legal contracts follow standard clause hierarchies. Instead of destroying this organization through chunking, preserve it and let the LLM use it.
To put it simply:
| Aspect | Vector RAG | Vectorless RAG |
|---|---|---|
| Organization | Semantic clusters (learned) | Hierarchical structure (explicit) |
| Query Processing | Embed + similarity score | Reason + navigate |
| Context | Isolated chunks | Full sections with hierarchy |
| Failure Mode | Returns similar-but-wrong content | Navigates to wrong section (debuggable) |
| Token Efficiency | Retrieves multiple overlapping chunks | Retrieves precise section |
| Explainability | Black box (why these chunks?) | Transparent (followed section path) |
| Cross-References | Cannot follow (chunks disconnected) | Native support (tree preserves links) |
Building Document Trees with Kudra:
Building Structure-Aware Extraction Pipelines
Kudra implements vectorless RAG foundations through structure-preserving extraction workflows that output hierarchical document metadata rather than flat text. Kudra’s extraction pipeline is designed to preserve document structure, not destroy it. While generic PDF parsers output flat text streams, Kudra builds explicit hierarchical representations.
The vectorless workflow follows this pipeline:
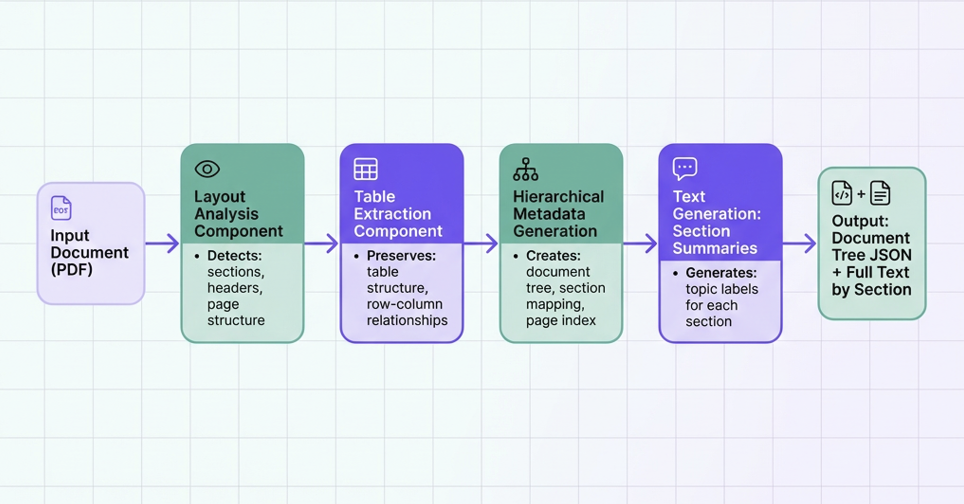
In Kudra the workflow setup would look like this:
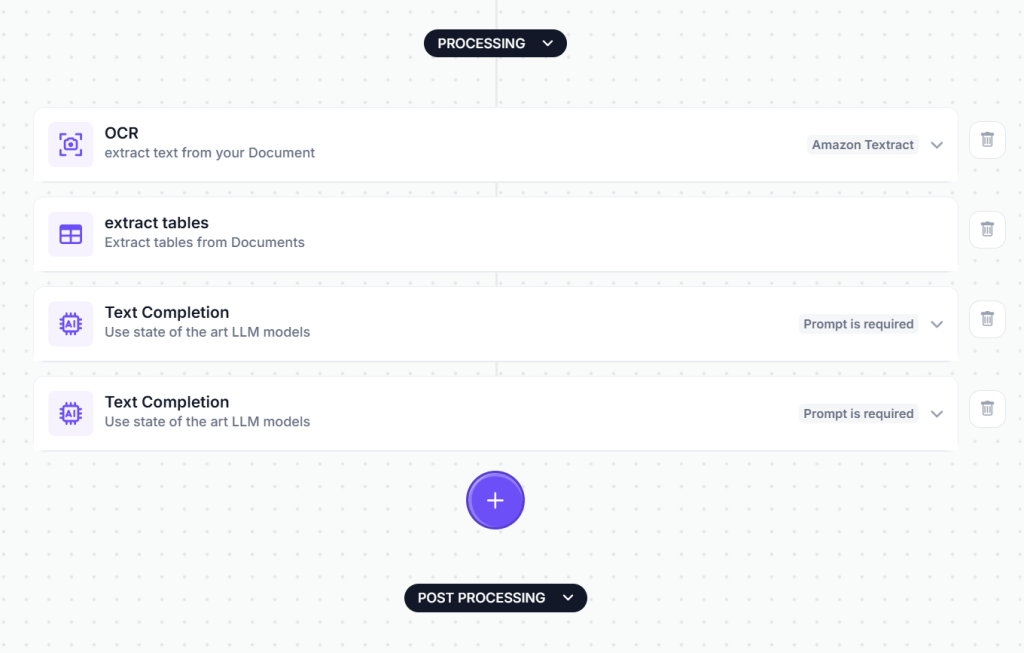
Each component contributes structural information that enables tree-based navigation.
Try Building Document Trees with Kudra
Component 1: Layout Analysis (Structure Detection)
Purpose: Identify document structure (sections, headers, subsections) before extraction
Why Structure Detection Matters: Documents encode meaning through formatting and position. A bold, larger font indicates a section header. Indentation signals hierarchy. Page breaks separate major sections. Layout analysis captures this visual structure that pure text extraction destroys.
Kudra’s Layout Analysis Approach:
- Computer vision models detect visual hierarchies (font size, bold, indentation)
- Section headers identified by formatting patterns
- Hierarchical relationships inferred from visual nesting
- Page boundaries preserved with section mappings
- Output: Structural skeleton of the document
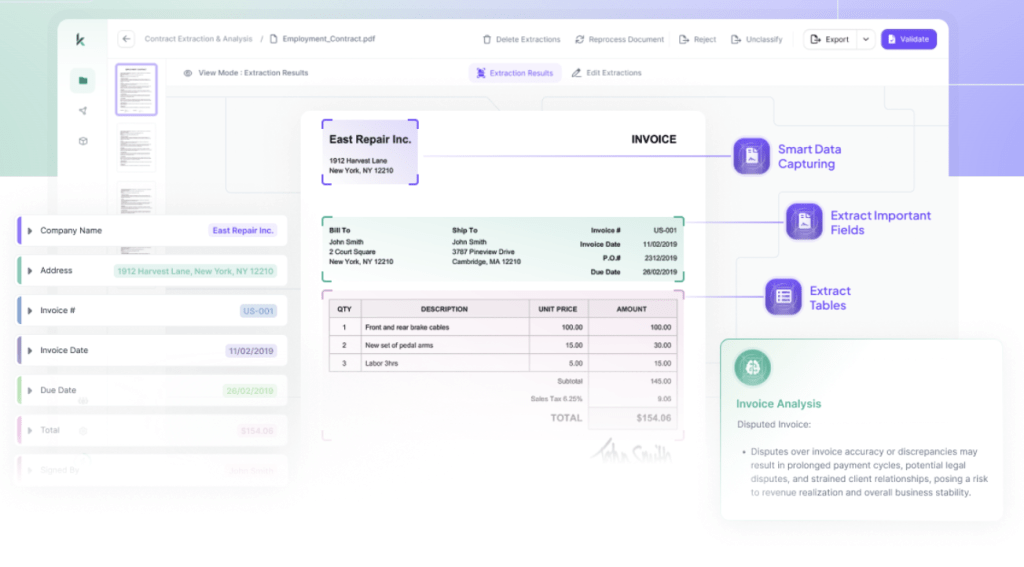
This structural metadata becomes the foundation of the document tree.
Component 2: Table Extraction (Structural Data)
Purpose: Extract tables with structure intact (essential for financial/medical documents)
Kudra’s Table Extraction (same as knowledge distillation blog):
- Detects table boundaries and cell structures
- Preserves row-column relationships
- Maintains table position within document hierarchy
- Links tables to parent sections
Integration with Document Tree: Tables are indexed by section:
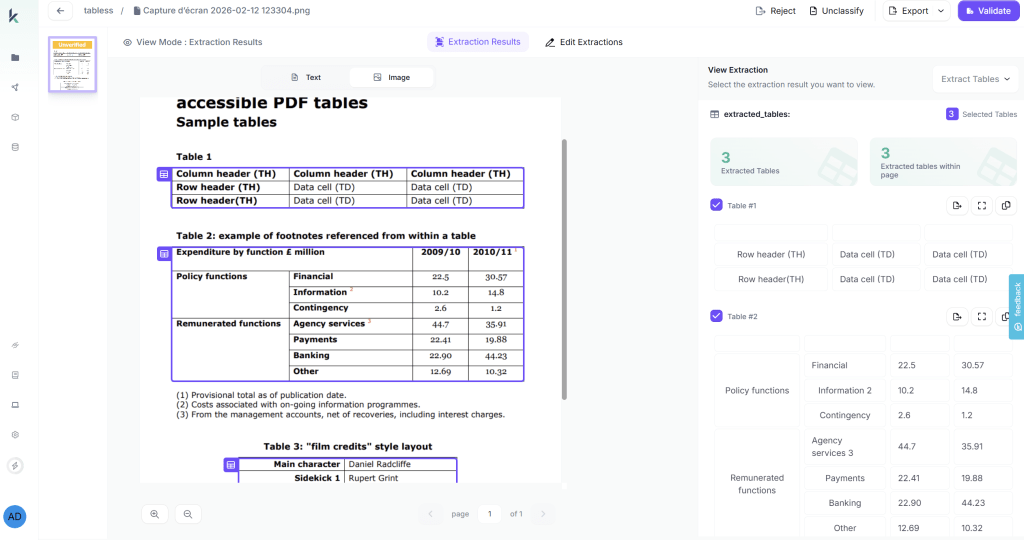
This enables queries that require table information to navigate directly to relevant tables.
Component 3: Hierarchical Metadata Generation
Purpose: Create the document tree structure for vectorless navigation
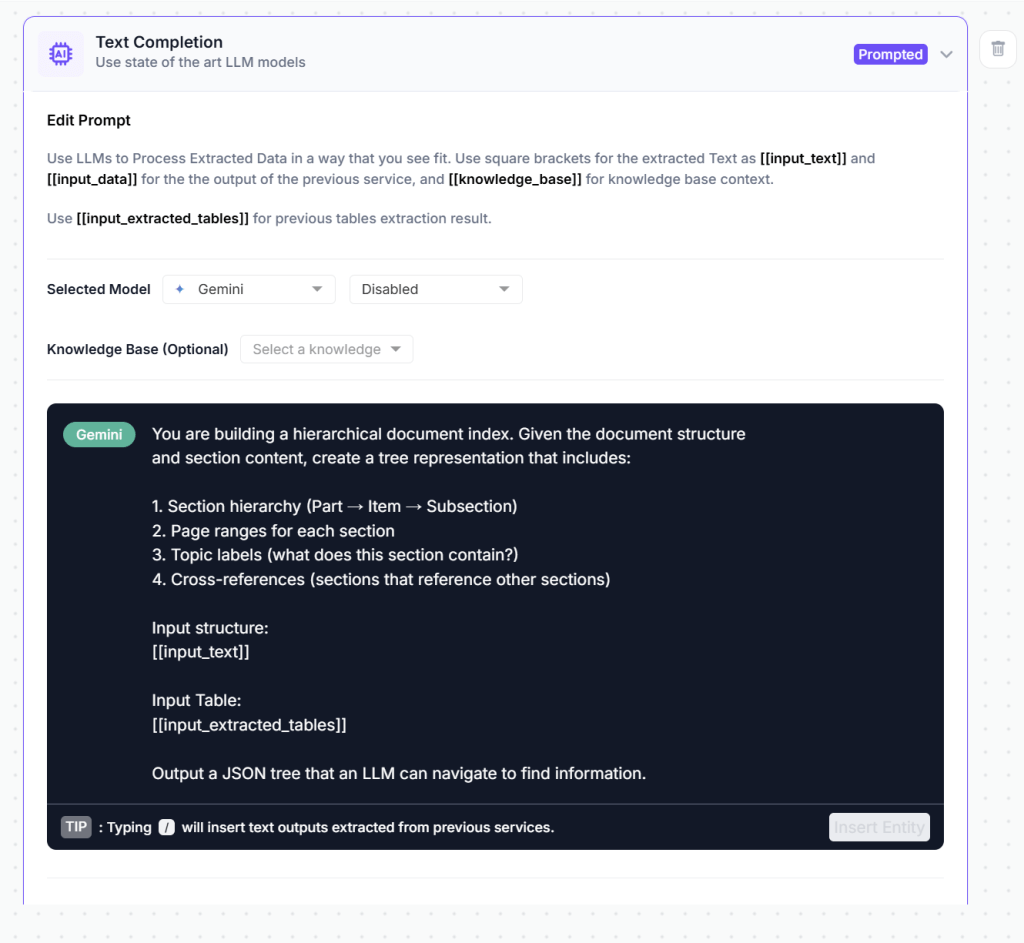
This will help our agent understand:
- Nested hierarchy: Sections contain subsections, preserving organization
- Page mappings: Every node knows which pages it spans
- Topic labels: Semantic descriptions of section content (enables reasoning)
- Table references: Links sections to structured data tables
- Full text access: Each section node can retrieve complete text (not chunked)
Component 4: Metadata & Section Summarization
Purpose: Generate semantic descriptions of each section’s content to enable navigational reasoning.
Why Metadata Matters: The document tree provides structure, but the LLM needs semantic labels to decide where to navigate. “Item 1” means nothing; “Financial Statements containing income statement, balance sheet, and cash flow data” enables reasoning.
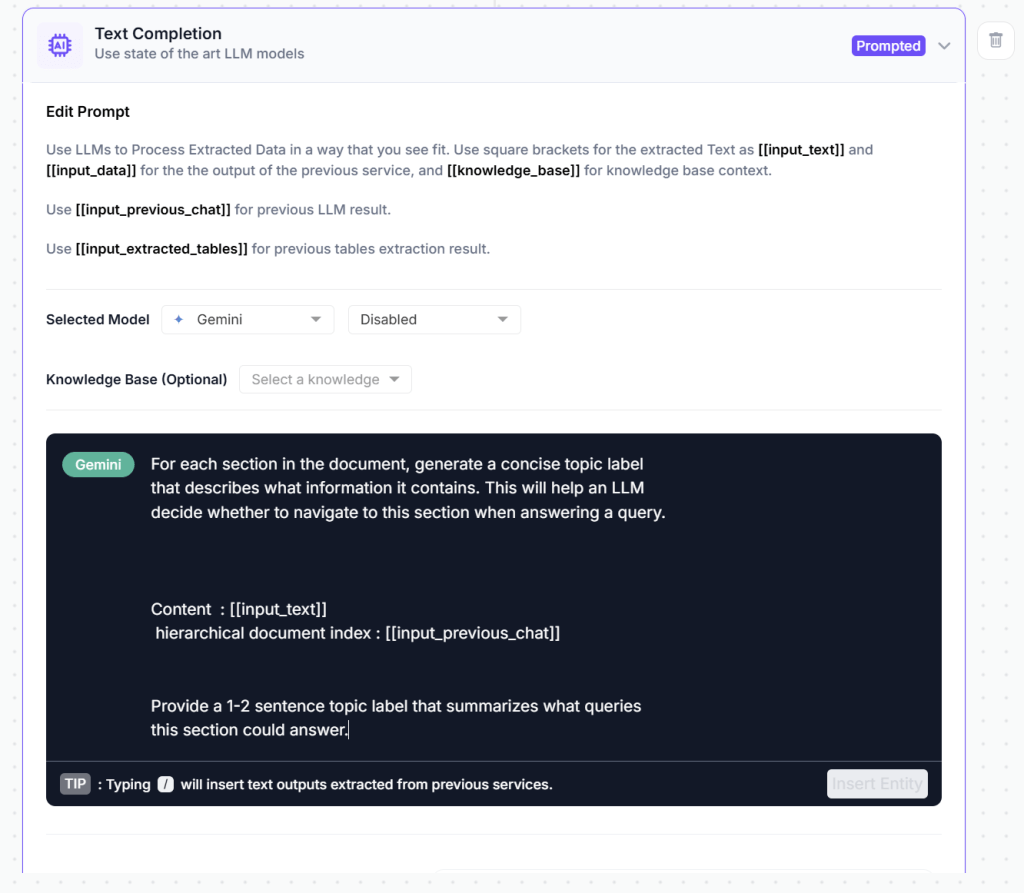
This becomes the substrate for vectorless retrieval. No embeddings. No chunking. No similarity search. Just structure and reasoning.
Want More Workflows?
Building Vectorless Agents
When Kudra processes a document, it outputs a structured JSON file containing the complete document tree, table data, and metadata. This JSON becomes the navigation substrate for your agentic RAG system. Instead of loading thousands of text chunks into a vector database, you load one structured document representation. This single JSON file replaces hundreds of embedded chunks. Your agent loads it once and navigates through the structure.

How the agent uses this:
You load the Kudra JSON into your agent’s context (or vector DB, or knowledge base)
Agent navigation happens in 2 ways:
Option A: Direct JSON traversal (true vectorless)
- Agent receives the document tree structure as part of its context
- LLM reasons: “User asks about Q3 revenue → I need the ‘income_statement’ section”
- Agent code does:
sections.find(s => s.id === "income_statement").full_text - Retrieves the exact section text
Option B: Semantic search on metadata (hybrid approach)
- You embed the section metadata (topics, titles, summaries) only
- Agent searches: “Q3 revenue” → matches section with topics=[“revenue”, “expenses”]
- But instead of returning chunks, returns the FULL section with structure intact
For our agent we will do the following workflow:
- Document Ingestion: Kudra extraction → Document tree JSON
- Tree Storage: Load into document store (no embeddings needed)
- Agent Deployment: Define navigation, planning, synthesis agents
- Query Processing: Planning agent decomposes query → Navigation agent traverses tree → Synthesis agent generates answer with citations
- Response: Final answer with transparent navigation path
Design Principles
1. Agents Navigate Trees, Not Chunks Never send agents flat text chunks. Always provide the document tree structure. Agents reason about “where to look” using section titles, hierarchy, and topic labels.
2. Multi-Step Navigation for Complex Queries Queries requiring comparisons or multi-section synthesis benefit from multiple navigation steps:
- Navigate to section A → retrieve data
- Navigate to section B → retrieve comparable data
- Synthesize across both
This sequential navigation (impossible with vector retrieval) enables sophisticated analysis.
3. Citation by Navigation Path Every answer includes the navigation path: “Part I → Item 2 → MD&A → Results of Operations (pages 15-17)”. Users can verify by following the same path in the source document.
4. Cross-Reference Following When agents encounter references (“see Note 12”), they navigate the tree to that section and retrieve content. This behavior mirrors human reading.
5. Section-Aware Context Windows Retrieve complete sections (5-10 pages) rather than fragments. Modern LLMs (200K+ context) can handle full sections, providing better context than chunk fragments.
Agent Behavior: Vector vs. Vectorless
After testing both agents on the same query, we clearly observed how the underlying search strategy directly shapes agent behavior, reasoning quality, and confidence. The screenshots below highlight how each approach impacts the agent’s ability to analyze, attribute, and synthesize information.
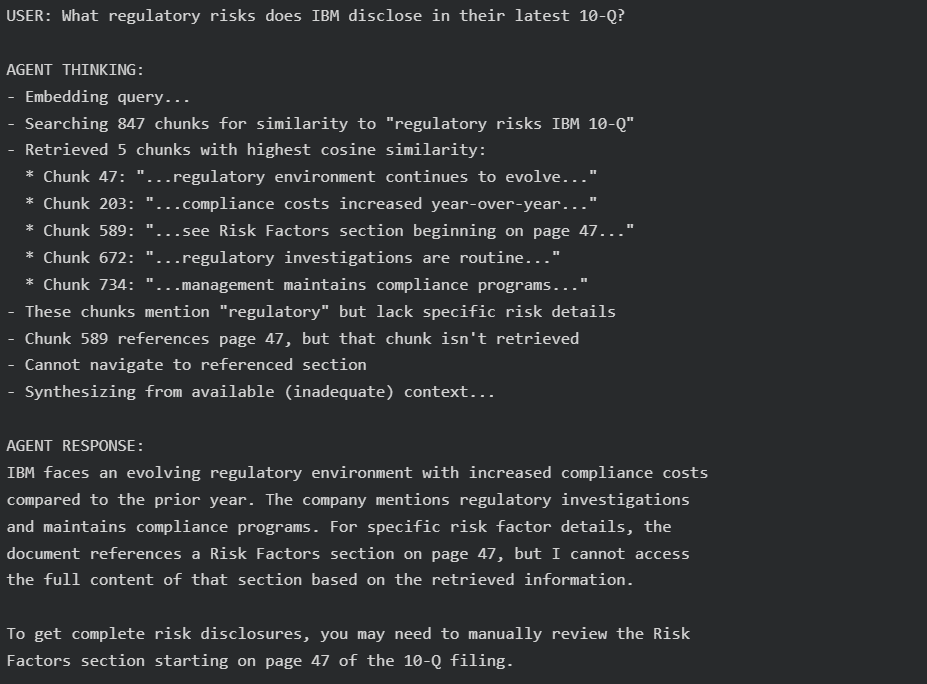
The similarity-based system retrieved scattered chunks that merely mentioned “regulatory” without accessing the actual Risk Factors section. It matched keywords instead of document structure, pulled cross-references without the referenced content, and produced a fragmented, low-confidence answer. The result was incomplete, hedged, token-inefficient, and required manual follow-up, undermining the purpose of automation.

In contrast, The structure-aware system navigated directly to Item 1A – Risk Factors, retrieved the full section, and extracted specific, quantified regulatory risks with exact page citations. By reasoning over document hierarchy instead of embeddings alone, it delivered a comprehensive, high-confidence answer with fewer tokens and no gaps.
Final Thoughts
Similarity search has been the default for RAG systems because it seemed like the only scalable approach to document retrieval. But production deployments reveal its limitations: context collapse from chunking, semantic ambiguity in ranking, token waste from imprecise retrieval, and opacity in debugging.
Vectorless RAG replaces matching with navigation. Documents are structured information hierarchies, not semantic soup. Financial reports, medical records, and legal contracts organize information deliberately. By preserving this structure and enabling LLMs to reason through it, vectorless systems achieve what vector search cannot: precise retrieval with transparent provenance.
The teams architecting next-generation RAG systems face a choice. They can continue optimizing embedding models and rerankers, pursuing marginal gains while the fundamental architectural problem persists. Or they can adopt structure-aware retrieval, building systems that navigate documents the way humans do—by understanding where information lives, not by guessing based on semantic similarity.
Kudra’s extraction pipeline transforms complex documents into navigable trees: hierarchical section structures, preserved table relationships, semantic metadata for reasoning, and cross-reference resolution. These become the substrate for agentic RAG systems that reason through structure, retrieve precise context, and generate answers with auditable citations. The performance impact isn’t incremental, it’s the difference between systems that hedge due to incomplete context and systems that answer confidently with complete information.