Building an AI agent isn’t technically hard. You can spin one up in a weekend: connect an LLM, bolt on a few tools, add conversation history, and it feels intelligent. It answers questions, calls APIs, maybe even drafts reports.
However, when left alone with real workloads, agents reveal their weaknesses. They overthink simple tasks. They forget critical constraints. They spiral into recursive reasoning. They quietly multiply API calls until your bill becomes the loudest signal in the system. What worked beautifully in a controlled test environment becomes unpredictable the moment stakes and scale enter the picture.
Reliable agents aren’t prompt tricks wrapped around an LLM. They’re carefully designed systems with boundaries, feedback loops, cost controls, memory strategies, and failure containment. Without those foundations, you don’t have an autonomous worker, you have an expensive experiment running unsupervised.
This article explores the ten architectural principles that separate fragile prototypes from agents you can trust to operate independently in 2026.
MCP: The Universal Plugin Layer for Agents
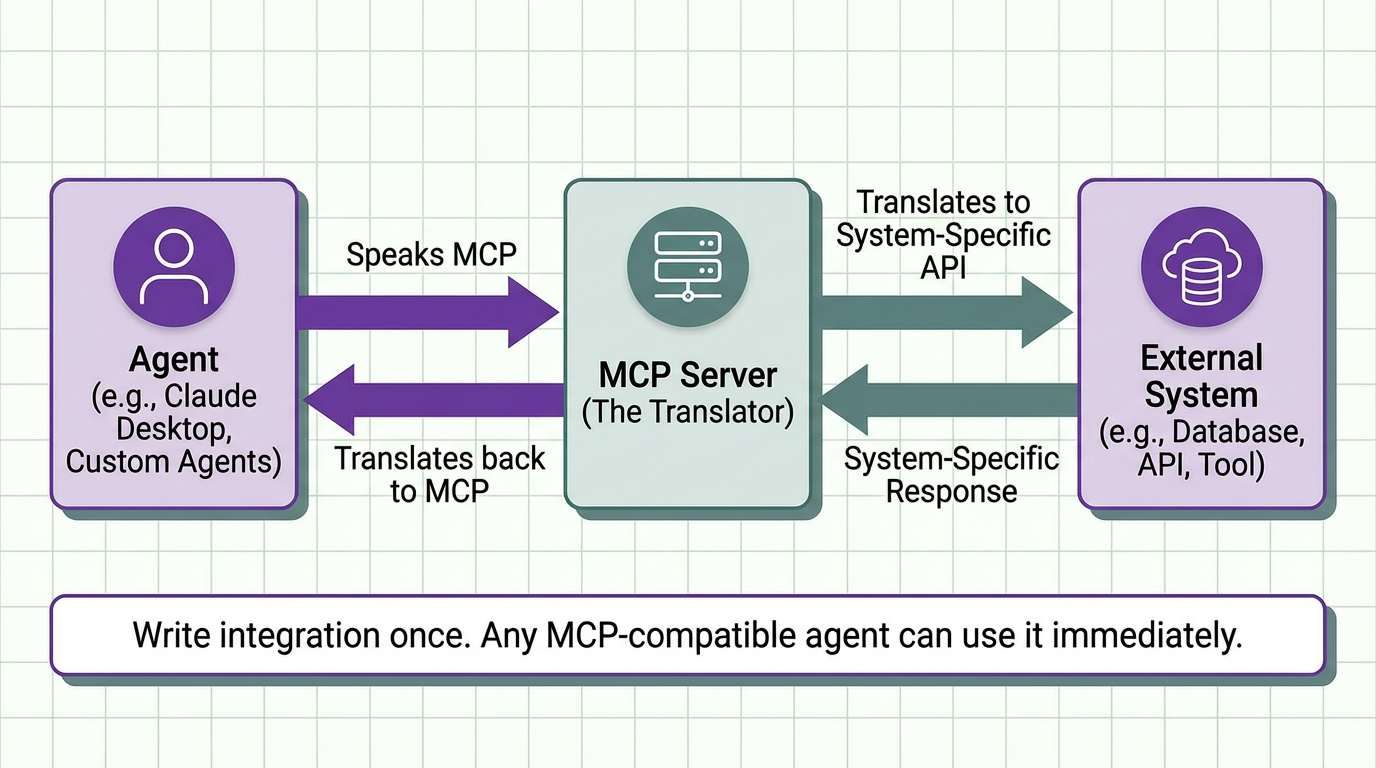
MCP (Model Context Protocol) is a standardized way for AI systems to connect to external tools, data sources, and services. Introduced by Anthropic, it acts like a universal adapter for agents.
If APIs were the infrastructure of the web, MCP is the infrastructure for agent tooling.
Instead of writing a custom integration for every model and framework, you implement MCP once. Any MCP-compatible agent can then discover and use that tool automatically.
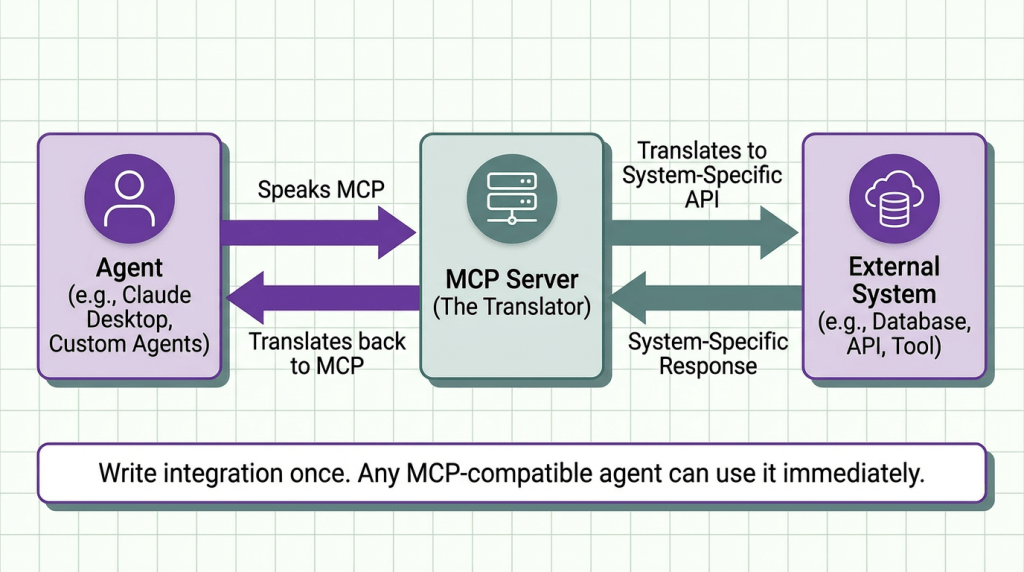
MCP defines three core primitives:
- Resources – Files, database entries, API endpoints the agent can read
- Tools – Functions the agent can execute (search, create, update)
- Prompts – Reusable prompt templates with parameters
When an agent needs to access Google Drive:
1. Agent asks MCP server: "What resources are available?"
2. MCP server returns: ["drive://folder1/doc1.pdf", "drive://folder2/data.csv"]
3. Agent selects resource and requests content
4. MCP server fetches from Google Drive API and returnsThe agent never touches Google Drive directly. It only knows MCP.
Tool Calling vs Function Calling
These terms are used interchangeably but represent fundamentally different execution models. Understanding the distinction prevents critical bugs in production agents.
Function Calling (Deterministic Execution)
The LLM generates structured function parameters, your code executes the function immediately, and the result goes back to the LLM.

The LLM never actually executes anything. It just generates the function name and parameters as structured data. Your orchestration layer executes it.
Tool Calling (Agent-Directed Execution)
The agent has autonomous access to tools and decides when and how to invoke them through an iterative loop.
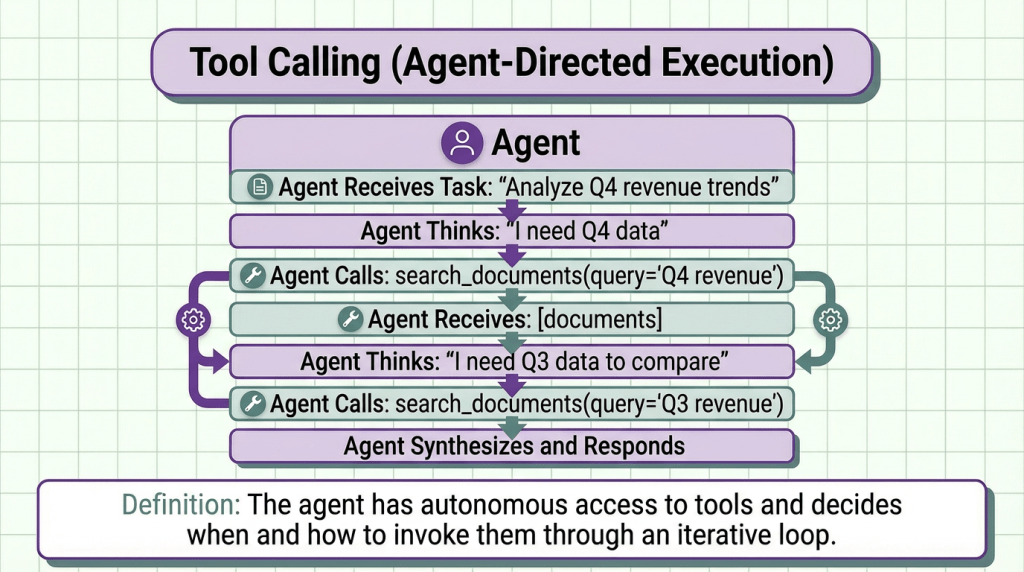
The key difference here is iterative decision-making. The agent can chain multiple tool calls, use outputs from one tool to inform the next, and adapt based on intermediate results.
Recommendation: Start with function calling for deterministic workflows (data lookups, simple transformations). Upgrade to tool calling when you need agents to handle ambiguous queries requiring iterative reasoning.
Agentic Loops and Termination Conditions
The core of any autonomous agent is its decision loop, the cycle of thinking, acting, and observing that continues until the task is complete. This is where most production agents fail catastrophically.

Simple in theory. Disastrous in practice if you don’t handle termination correctly.
What can go wrong:
- Infinite Loops : Agent never decides it’s done
- Premature Termination : Agent gives up too early
- Resource Exhaustion : Agent continues until budget/time runs out
- Stuck States : Agent repeats the same failed action indefinitely
To solve these issues use a combination of:
- Resource budgets as hard limits (safety)
- Goal achievement or confidence as primary termination (quality)
- Loop detection to prevent stuck states (reliability)
Memory Architecture (Short-term vs Long-term)
Agent memory isn’t a single concept, it’s a hierarchy of different storage mechanisms optimized for different access patterns and time horizons. Production agents that treat memory as “just store everything in a vector DB” hit scaling and quality problems within days.
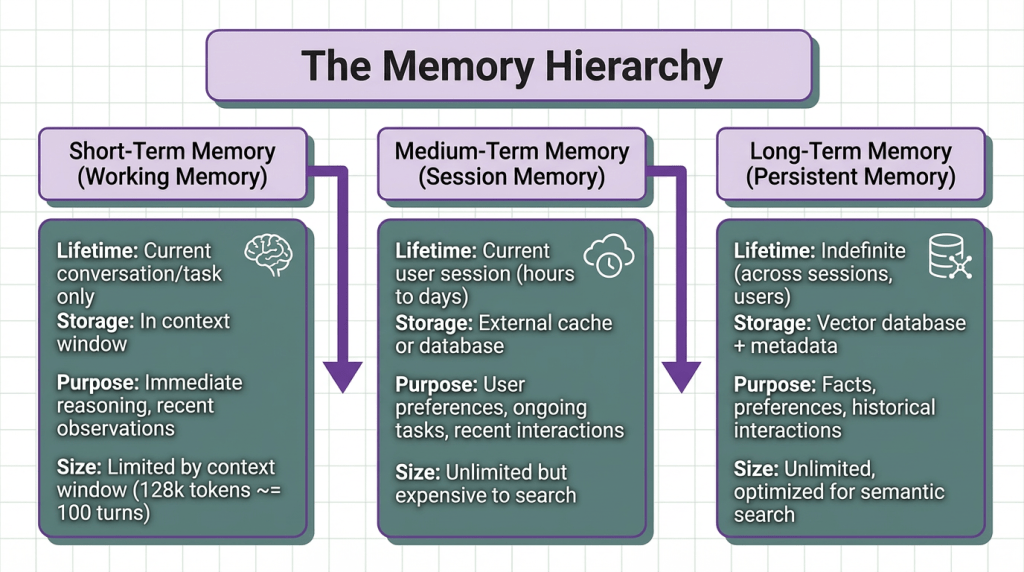
Most agents only implement short-term (context window) and long-term (vector DB), skipping medium-term entirely. This causes problems. Studies on transformer attention show a “lost in the middle” phenomenon. Information in the middle 50% of the context window has 30-40% lower retrieval accuracy than information at the beginning or end.
Create a session memory that sits between short-term and long-term, caching:
- User preferences stated this session
- Entities and facts mentioned recently (last 1-2 hours)
- Ongoing task state
- Recent failed actions (to avoid repeating mistakes)
Context Window Management
Context windows have grown from 4k tokens to 200k+ tokens, leading developers to assume “context is infinite.” This assumption kills production agents. Large context windows don’t solve the fundamental problems, they just delay them and add new failure modes.

Research shows that when relevant information is placed in different positions within a long context:
| Position in Context | Retrieval Accuracy |
|---|---|
| First 10% | 87% |
| Middle 50% | 52% |
| Last 10% | 81% |
Information in the middle gets effectively ignored despite being “in context”. Instead start with hierarchical context structure (low effort, immediate gains). Add compression when costs become an issue. Reserve multi-pass for complex analytical tasks.
RAG Using Agents (When and How)
Retrieval-augmented agents combine LLM reasoning with external knowledge retrieval. But knowing when to retrieve and how to integrate retrieved information separates functional agents from production-grade ones.

Before embedding, it’s better to extract structured information:
- Better retrieval precision : Search returns the table, not a page with the table buried in noise
- Metadata filtering : Query uses metadata, not just semantic search
- Proper context : Each chunk includes doc title and section heading for context
| Strategy | Latency | Precision | Context Efficiency | Best For |
|---|---|---|---|---|
| Auto-retrieve always | High | Low | Poor | Simple Q&A |
| Agent-directed | Variable | High | Good | Complex research |
| Iterative | Very high | Very high | Excellent | Multi-hop reasoning |
| Hierarchical | Medium | High | Excellent | Large doc corpus |
Multi-Agent Orchestration Patterns
Single agents hit capability limits quickly. Multi-agent systems divide complex tasks across specialized agents, but naive orchestration creates more problems than it solves.
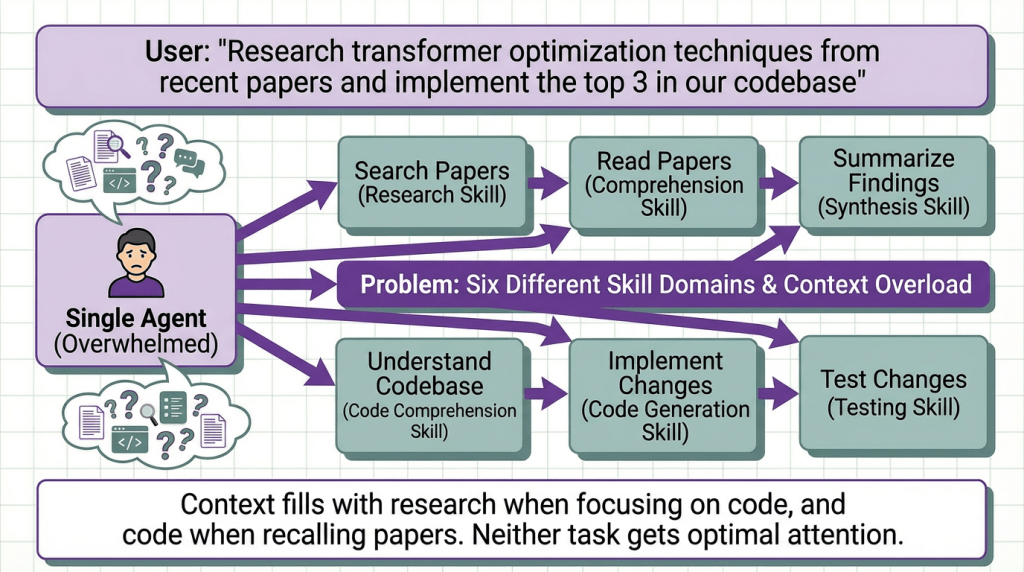
To solve this different agents can be optimized for different tasks:
- Research agent: Tuned for paper search and summarization
- Code agent: Tuned for code generation and testing
- Coordinator agent: Orchestrates the workflow
Each agent maintains focused context for its domain.
The Different Multi-Agent Orchestration Patterns
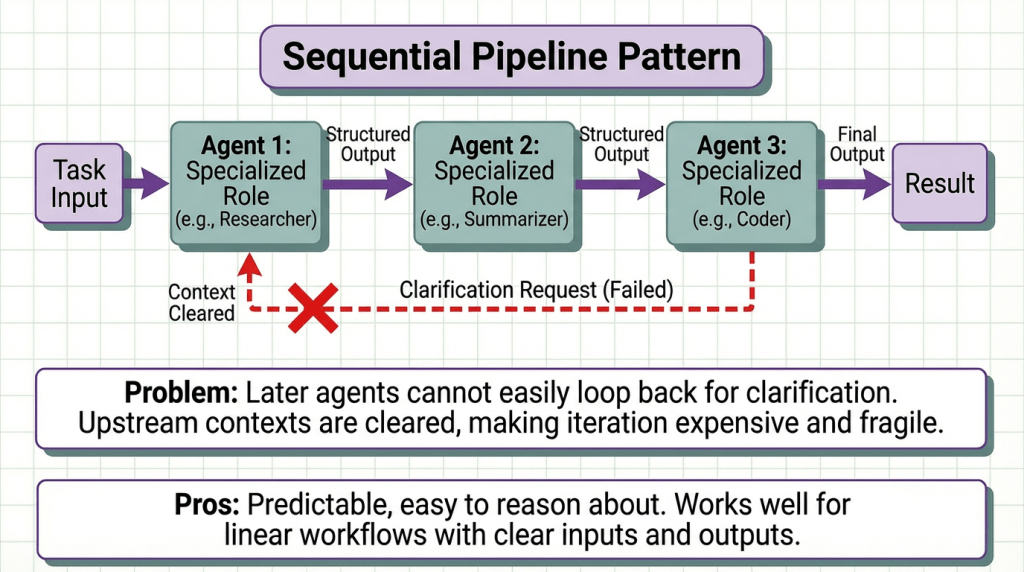
Sequential Pipeline: This pattern moves a task through a fixed chain of specialized agents, where each performs one role and passes structured output to the next. It works well for linear workflows with clear inputs and outputs, making the system predictable and easy to reason about. The problem arises when a later agent needs clarification from an earlier step. Since upstream agents usually clear their context after finishing, there’s no clean way to loop back. Iteration becomes expensive, often requiring the entire pipeline to restart, which makes the system fragile in ambiguous or evolving tasks.
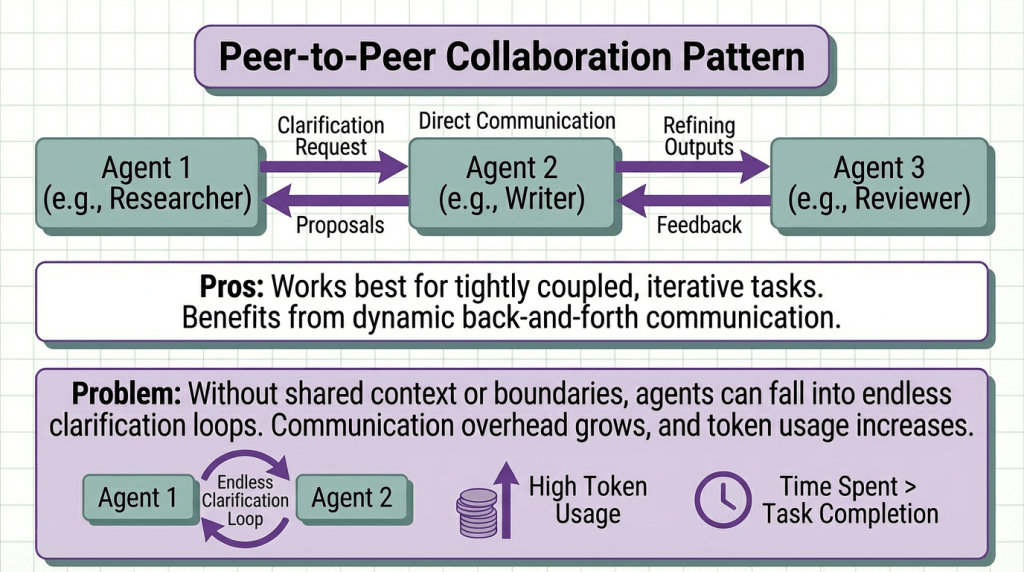
Peer-to-Peer Collaboration: In this decentralized model, agents communicate directly, requesting clarification, proposing ideas, and refining outputs together. It works best for tightly coupled, iterative tasks that benefit from dynamic back-and-forth. However, without shared context or strict communication boundaries, agents can fall into endless clarification loops. Communication overhead grows, token usage increases, and the system risks spending more time discussing the task than actually completing it.
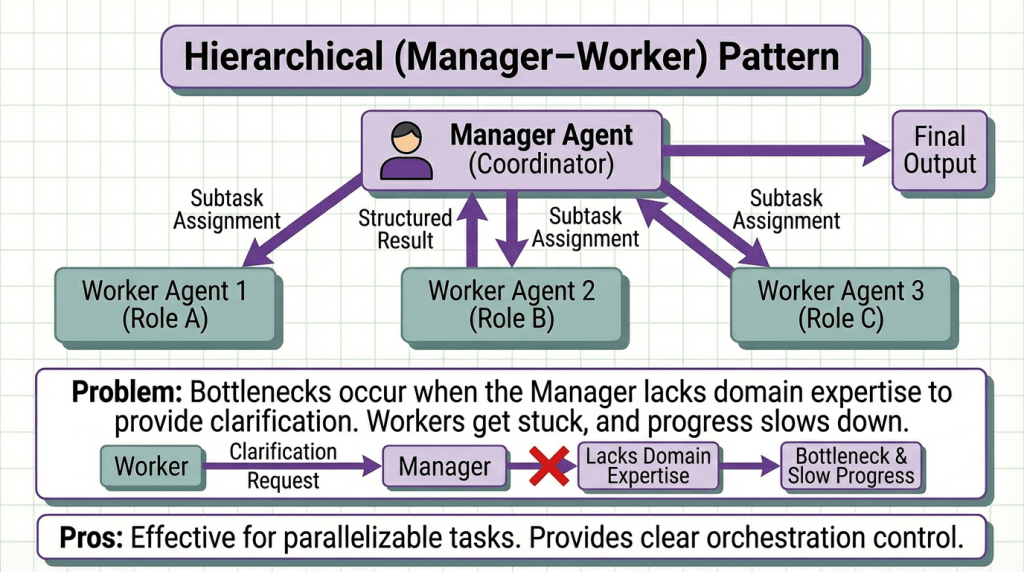
Recommendation: Start with Sequential Pipeline (simplest). Upgrade to Hierarchical when parallelization matters. Only use Peer-to-Peer for genuinely collaborative tasks (code review discussions, design debates).
Final Thoughts
The agent landscape is evolving rapidly. Standards like MCP are emerging. Models are getting cheaper and faster. But the fundamental challenges (memory management, cost control, error handling) remain architectural problems that frameworks alone won’t solve.
The developers who build reliable production agents understand these 8 concepts deeply. They design systems that gracefully handle failures, stay within budget, and maintain quality as complexity scales.
Start with these foundations. Master them before adding complexity. Your production agents will thank you.